初心者歓迎!AWSコンソールで始める初めてのDynamoDB!
はじめに
この資料は JAWS FESTA 2023 Kyushu で行われるハンズオンために書かれました。
イベントページはこちら。
手を動かしながら Amazon DynamoDB の基本を学ぶことができます。
自己紹介
- ニッシー ☆ === 西勇樹(Nishi Yuki)
- 株式会社ユーザベースに今年新卒入社しました。
- ソーシャル経済メディア「NewsPicks」の Web 版を作っています。
- 日本酒が好きです。
- SNS リンク
- 𝕏 (Twitter):https://twitter.com/yukinissie
- Facebook:https://www.facebook.com/yukinissie
- GitHub:https://github.com/yukinissie
1. 座学編[30分](13:05〜13:35)
1-1. Amazon DynamoDB の基本
Amazon DynamoDB(以下、DynamoDB) は高速で予測可能なパフォーマンスやシームレスなスケーラビリティを提供するフルマネージドでサーバーレスの key-value NoSQL データベースサービスです。
1-1-1. DynamoDB の利点
以下のような利点があります。
- 分散データベースの運用やスケーリングにかかる管理負荷を軽減
- ハードウェアのプロビジョニング、セットアップと設定、レプリケーション、ソフトウェアのパッチ適用、クラスタのスケーリングなどを心配する必要がなくなる
1-1-2. DynamoDB の特徴
DynamoDB では以下のような特徴があります。
- 任意の量のデータを格納および取得し、任意のレベルのリクエストトラフィックに対応できるデータベーステーブルの作成
- ダウンタイムやパフォーマンスの低下なしに、テーブルのスループット容量をスケールアップまたはスケールダウン
- AWS Management Console を使用した、リソースの使用率とパフォーマンスメトリクスの監視
- 他にもたくさんの特徴があります
- 詳細:AWS 公式サイト「Amazon DynamoDB の特徴」
1-1-3. DynamoDB の機能
DynamoDB では以下のような機能が提供されています。
- オンデマンドバックアップ機能
- 完全なバックアップを作成できる
- 詳細:AWS 公式ドキュメント「DynamoDB のオンデマンドバックアップおよび復元の使用」
- ポイントインタイムリカバリ機能
- リアルタイムでバックアップし任意の時点にテーブルを復元できる
- 詳細:AWS 公式ドキュメント「ポイントインタイムリカバリ: 仕組み」
- 期限切れの項目をテーブルから自動的に削除する機能
- 詳細:AWS 公式ドキュメント 「DynamoDB の有効期限 (TTL) を使用して項目を期限切れにする」
1-1-4. DynamoDB の高い可用性と耐久性
- 一貫性のある高速なパフォーマンスを維持しながら、スループットとストレージ要件を処理するために十分な数のサーバーにテーブルのデータとトラフィックを自動的に分散する
- すべてのデータはソリッドステートディスク(SSD)に保存され、AWS リージョン内の複数の アベイラビリティーゾーン(AZ) に自動的にレプリケートされ、ビルトインの高可用性とデータの耐久性を提供する
- グローバルテーブルを使用すると、AWS リージョン間で DynamoDB のテーブルを同期させることが可能
- 詳細:AWS 公式ドキュメント「グローバルテーブル – DynamoDB の複数リージョンレプリケーション」
1-1-5. ユースケース
以下のような1秒間に数百万回のリクエストを処理する必要がある業界で使われています。
- アドテック(広告)
- 小売り
- ソフトウェアとインターネット
- ゲーム
- メディアとエンターテイメント
- 銀行と金融
詳細は AWS 公式サイト「Amazon DynamoDB」のユースケースセクションをご覧ください。
1-1-6. 料金
DynamoDB の課金対象は大きく分けて以下の 2 つです。
- DynamoDB テーブル内のデータの読み取り、書き込み、保存
- 有効化したオプション機能の使用
さらに 1. には「オンデマンド」と「プロビジョニング」という 2 種類のキャパシティモードがあり、それぞれのモードにおけるテーブルの読み書き処理について別個の請求オプションがあります。
詳しくはAWS公式サイト「Amazon DynamoDB 料金」をご覧ください。
無料利用枠(無期限無料)
Amazon DynamoDBには無期限の無料利用枠があります。
1-1-7. 公式ドキュメント
安心安全 AWS 公式ドキュメントのリンクはこちらです↓
例えば以下のようなものが載っています。
今回のハンズオンは公式ドキュメントの内容を元に作成しています。
1-1-8. 学習リソース
- 公式チュートリアル
- API リファレンス
- AWS CLI もしくは AWS SDK から DynamoDB を操作する際に参照する
- よくある質問
- フォーラム
- DynamoDB に関する質問や issue(技術的課題)を投稿することができる
- 公式ブログ
1-2. DynamoDB の基本用語
1-2-1. テーブル・項目・属性
- テーブル(Table)
- DynamoDB はデータをテーブルに保存する
- テーブルは複数の項目の集合
- 項目(Item)
- 各テーブルにはゼロ以上の項目が含まれている
- 項目は他のすべての項目間で一意に識別可能な属性の集合
- 他のデータベースでいうところの「行(レコード)」に似ている
- テーブルに保存できる項目数に制限はない
- 属性(Attribute)
- 各項目は 1 つ以上の属性で構成される
- 属性は基盤となるデータ要素であり、それ以上分割する必要がないものである
- 他のデータベースでいうところの「列(フィールド)」に似ている
- プライマリキー以外はスキーマレス
- 属性のほとんどは 1 つの値のみを持つことができる
- 例:文字列、数値
- 一部の項目には、ネストされた属性 (アドレス) がある
- ネストの深さが最大 32 レベルの属性をサポート
1-2-2. 属性の詳細 (1/2)
属性は、基盤となるデータ要素であり、それ以上分割する必要がないものです。
- 命名規則あり
- 1 文字以上の長さ、64 KB 未満のサイズにする必要あり
- できるだけ短くすることがベストプラクティス
- 属性名がストレージとスループットの使用量の測定に含まれるため、属性名を短くすることで消費される読み取りリクエストユニットを減らすことができる
- 以下は例外で、これらの属性名は 255 文字以下である必要がある
- セカンダリインデックスのパーティションキー名
- セカンダリインデックスのソートキー名
- ユーザー指定の射影された属性の名前 (ローカルセカンダリインデックスにのみ適用)
- 参考:AWS 公式ドキュメント「Amazon DynamoDB でサポートされるデータ型と命名規則」
1-2-2. 属性の詳細 (2/2)
- データ型
- スカラー型
- 数値
- 文字列
- バイナリ(base64 エンコードされたデータ)
- ブール
- null
- ドキュメント型
- リスト
- マップ
- スカラー型
- セット型
- 文字セット
- 数値セット
- バイナリセット
参考:AWS 公式ドキュメント「Amazon DynamoDB のコアコンポーネント」
1-2-3. 項目の詳細
項目は、他のすべての項目間で一意に識別可能な属性の集合です。
- 各テーブルにゼロ以上の項目が含まれている
- 他のすべての項目間で一意に識別可能な属性のグループである
- 多くの点で他のデータベースシステムの行、レコード、またはタプルに似ている
- テーブルに保存できる項目数に制限はなし
参考:AWS 公式ドキュメント「Amazon DynamoDB のコアコンポーネント」
1-2-4. テーブルの詳細
テーブルの重要な用語は以下の通りです。
- テーブル名
- 状態
- プライマリキー
- セカンダリインデックス
- 読み取り/書き込みキャパシティモード
- テーブルクラス
- 削除保護
それぞれの用語について説明していきます。
テーブル名
その名の通りテーブルの名前です。
- 命名規則あり
- すべての名前は UTF-8 を使用してエンコードする必要があり
- 大文字と小文字が区別される
- テーブル名とインデックス名の長さは 3 ~ 255 文字
- 次の文字が使える
a-zA-Z0-9_(下線)-(ダッシュ).(ドット)
- 現在の AWS アカウントとリージョン内で一意である必要がある
- 例 1)米国東部 (バージニア北部) に People テーブルを作成した場合、米国東部 (バージニア北部) に追加で同名の People テーブルを作成することはできない
- 例 2)米国東部 (バージニア北部) に People テーブルを作成し、欧州 (アイルランド) に別の People テーブルを作成できるが、これらの 2 つのテーブルは全くの別物である
詳細については、AWS 公式ドキュメント「Amazon DynamoDB でサポートされるデータ型と命名規則」を参照してください。
状態
現在のテーブルの状態について知ることができます。AWS SDK for Java V2 では以下のような状態が定義されています。(一部抜粋)
- ACTIVE
- ARCHIVED
- ARCHIVING
- CREATING
- DELETING
- UPDATING
プライマリキー
テーブルの項目を一意に識別するために使用される属性または属性のセットです。
DynamoDB は 2 種類の異なるプライマリキーをサポートします。
- パーティションキーのみ
- パーティションキーとソートキーの組み合わせ
プライマリキー属性はスカラー値である必要があり、許可される唯一のデータ型は、文字列、数値、またはバイナリです。
参考:AWS 公式ドキュメント「Amazon DynamoDB のコアコンポーネント」
パーティションキー
1 つの属性で構成されたシンプルなプライマリキーです。
- DynamoDB はデータをパーティションと呼ばれる物理ストレージに保存する
- パーティションキーを利用して生成したハッシュ値によって、データはパーティションに分散配置される
- パーティションは、AWS リージョン内の複数のアベイラビリティーゾーン間で自動的にレプリケート(複製)される
- パーティション管理は DynamoDB によって完全に処理される
- パーティションを管理者が管理する必要はない
ソートキー
同じパーティションキー値を持つすべての項目をソートしてまとめて保管するための複合プライマリキーです。
- 同じパーティションキーを持つ他の項目とソートキーの昇順で項目が保存される
- テーブルから項目を読み込むには、パーティションのキーバリューとソートキーのキーバリューを指定する必要がある
- 目的の項目に同じパーティションキーバリューがある場合、単一のオペレーション (
Query) でテーブルから複数の項目を読み取ることができる
- パーティションキーとソートキーが存在するテーブルでは、同じパーティションのキーバリューが複数の項目に割り当てられることがある
- ソートキー値は複数の項目で異なる必要がある
セカンダリインデックス
- テーブルに 1 つ以上のセカンダリインデックスを作成できる
- セカンダリインデックスでは、プライマリキーに対するクエリに加えて、代替キーを使用して、テーブル内のデータのクエリを行うことができる
- インデックスの使用は必須ではありませんが、インデックスを使用すると、データのクエリを行う際にアプリケーションの柔軟性が高まる
- テーブルにグローバルセカンダリインデックスを作成すると、テーブルから行う場合とほぼ同じ方法でインデックスからデータを読み取ることができる
2 つのセカンダリインデックス
DynamoDB では、次の 2 種類のインデックスをサポートしています。
- グローバルセカンダリインデックス
- パーティションキーおよびソートキーを持つインデックス
- テーブルのものとは異なる場合がある
- ローカルセカンダリインデックス
- パーティションキーはテーブルと同じ
- ソートキーが異なるインデックスである
読み取り/書き込みキャパシティモード
テーブルで読み込みおよび書き込みを処理するためのキャパシティモードについて説明します。
- 2 つのキャパシティモードがある
- オンデマンドモード
- プロビジョニングモード (デフォルト、無料利用枠の対象)
- 読み取りおよび書き込みスループットの課金方法と容量の管理方法を制御する
- 参考:AWS 公式ドキュメント「読み取り/書き込みキャパシティモード」
オンデマンドモード (1/2)
オンデマンドキャパシティモードの特徴は以下の通りです。
- キャパシティプランなしで 1 秒あたりに数千ものリクエストを処理できる
- 読み取りおよび書き込みリクエストごとの支払い料金が用意されている
- 使用した分だけ課金される
オンデマンドモード (2/2)
オンデマンドキャパシティモードは以下のような場合に適しています。
- 不明なワークロードを含む新しいテーブルを作成する場合
- アプリケーションのトラフィックが予測不可能な場合
- わかりやすい従量課金制の支払いを希望する場合
- 参考:AWS 公式ドキュメント「読み取り/書き込みキャパシティモード」
プロビジョニングモード (1/2)
プロビジョニングキャパシティモードの特徴は以下の通りです。
- アプリケーションに必要な 1 秒あたりの読み込みと書き込みの回数を事前に指定する
- Auto Scaling を使用すると、トラフィックの変更に応じて、テーブルのプロビジョンドキャパシティーを自動的に調整できる
プロビジョニングモード (2/2)
プロビジョニングキャパシティモードは以下のような場合に適しています。
- アプリケーションのトラフィックが予測可能な場合
- トラフィックが一定した、または徐々に増加するアプリケーションを実行する場合
- キャパシティーの要件を予測してコストを管理できる場合
- 参考:AWS 公式ドキュメント「読み取り/書き込みキャパシティモード」
キャパシティユニット (1/2)
プロビジョニングモードのテーブルでは、読み取りキャパシティユニット (RCU) と書き込みキャパシティユニット (WCU) の観点でスループットキャパシティを指定できます。
- 1 読み込みキャパシティユニットは最大サイズが 4 KB までのサイズの項目について
- 1 秒あたり 1 回の強力な整合性のある読み込みができる
- 1 秒あたり 2 回の結果整合性のある読み込みができる
- トランザクションの読み込みリクエストでは、4 KB までの項目を 1 秒あたりに 1 回読み込むのに読み込みキャパシティユニットが 2 個必要である
- 4 KB より大きい項目を読み込む必要がある場合は追加の読み込みキャパシティユニットを消費する必要がある
- 必要な読み込みキャパシティユニットの最大数は、項目のサイズと、結果整合性のある読み込みまたは強力な整合性のある読み込みが必要かどうかによって異なる
- 詳細:AWS 公式ドキュメント「読み込みでのキャパシティユニットの消費」
キャパシティユニット (2/2)
- 1 書き込みキャパシティユニットは、最大サイズが 1 KB の項目について
- 1 秒あたり 1 回の書き込みができる
- 1 KB より大きい項目を書き込む必要がある場合は追加の書き込みキャパシティユニットを消費する必要がある
- トランザクションの書き込みリクエストでは、1 KB までの項目を 1 秒あたり 1 回書き込むのに書き込みキャパシティユニットが 2 個必要である
- 必要な書き込みキャパシティーユニットの合計数は、項目サイズに応じて異なる
- 詳細:AWS 公式ドキュメント「書き込みでのキャパシティユニットの消費」
参考:AWS 公式ドキュメント「読み取り/書き込みキャパシティモード」
テーブルクラス (1/2)
コストの最適化に役立つように設計された 2 つのテーブルクラスが用意されています。
- DynamoDB 標準テーブルクラス(デフォルト)
- 大半のワークロードで推奨
- DynamoDB Standard-Infrequent Access (DynamoDB 標準-IA) テーブルクラス
- ストレージが主要なコストとなるテーブル用に最適化
- アクセス頻度の低いデータを格納するテーブル
- アプリケーションログ
- 古いソーシャルメディアの投稿
- e コマースの注文履歴
- 過去のゲーム実績
テーブルクラス (2/2)
テーブルクラスに関する料金の詳細については、「Amazon DynamoDB の料金表」を参照してください。
参考:AWS 公式ドキュメント「テーブルクラス」
削除保護
削除保護はテーブルの削除を防ぐために使用される機能です。
- 削除保護を有効にすると、その間はテーブルを削除することができなくなる
休憩[10](13:40〜13:50)
2. 実習編[60](13:50〜14:40)
クレジットの登録
- アカウント名をクリックします
- 請求ダッシュボードをクリックします

- クレジットをクリック

- 「クレジットを適用」をクリックします

- プロモーションコードとセキュリティコードを入力します
- 「クレジットを適用」をクリックします

2-1. DynamoDB サービストップページの開き方
- AWS コンソールにログインして、ヘッダーにある検索窓をクリックします。
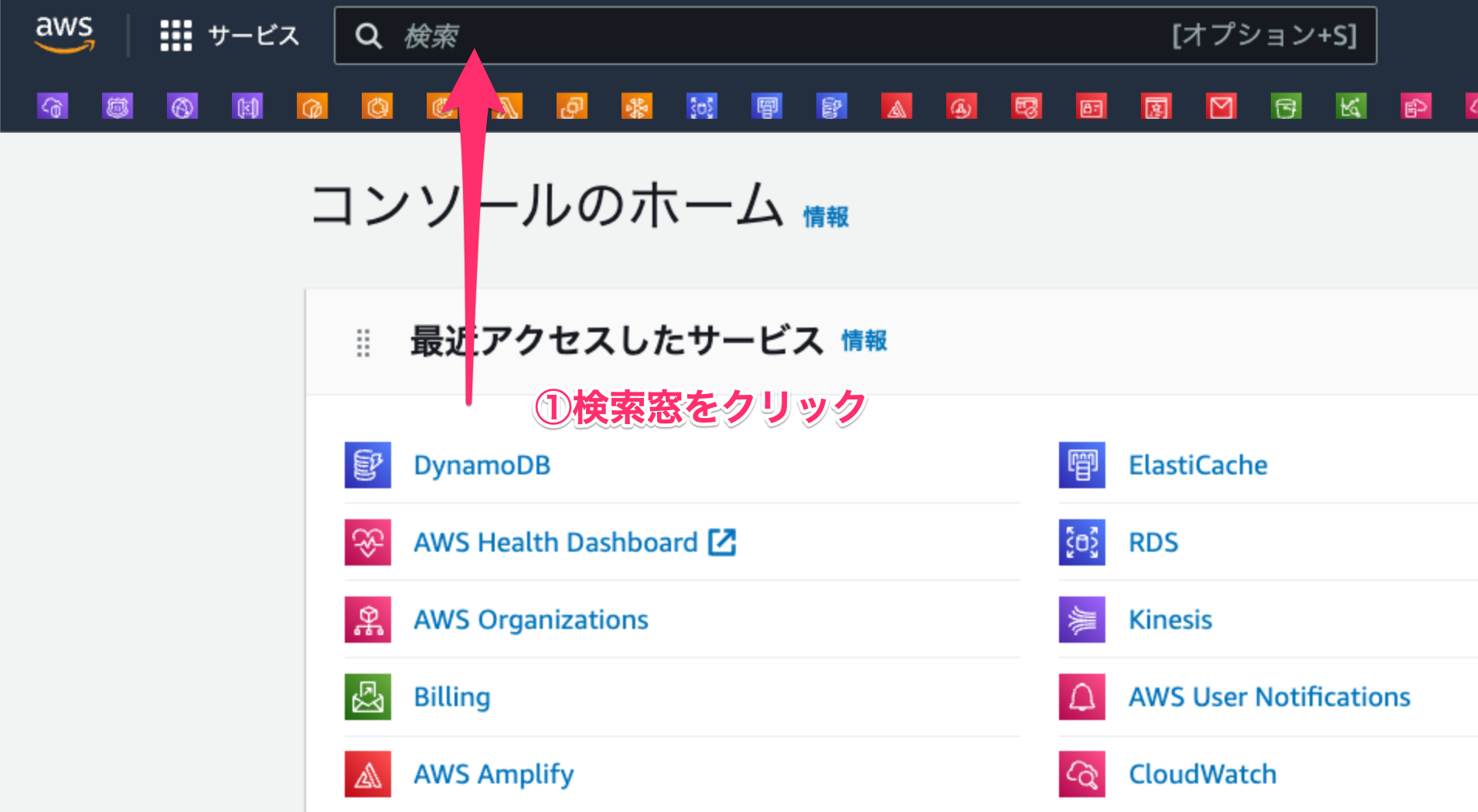
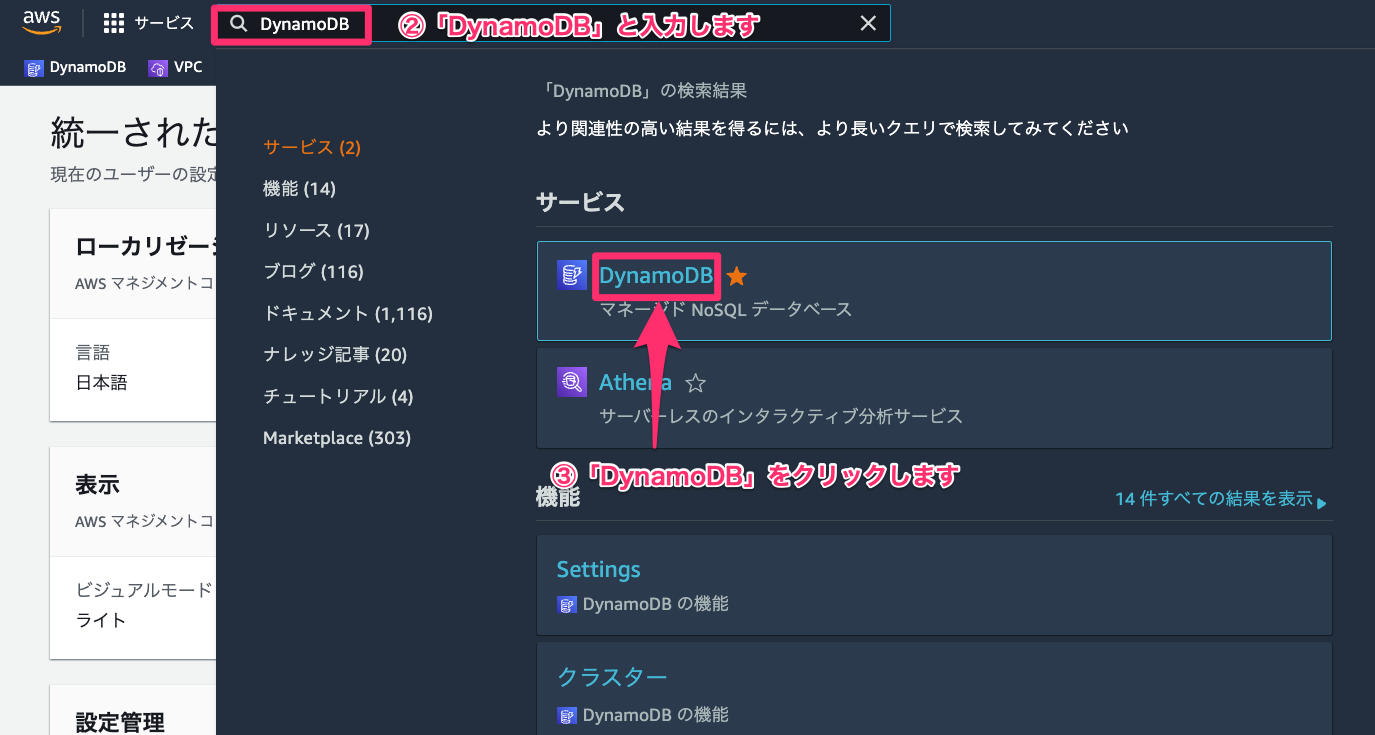
- 検索窓に「DynamoDB」と入力します。
- 検索結果の中から「DynamoDB」をクリックします。
- DynamoDB サービスのトップページが開きます。
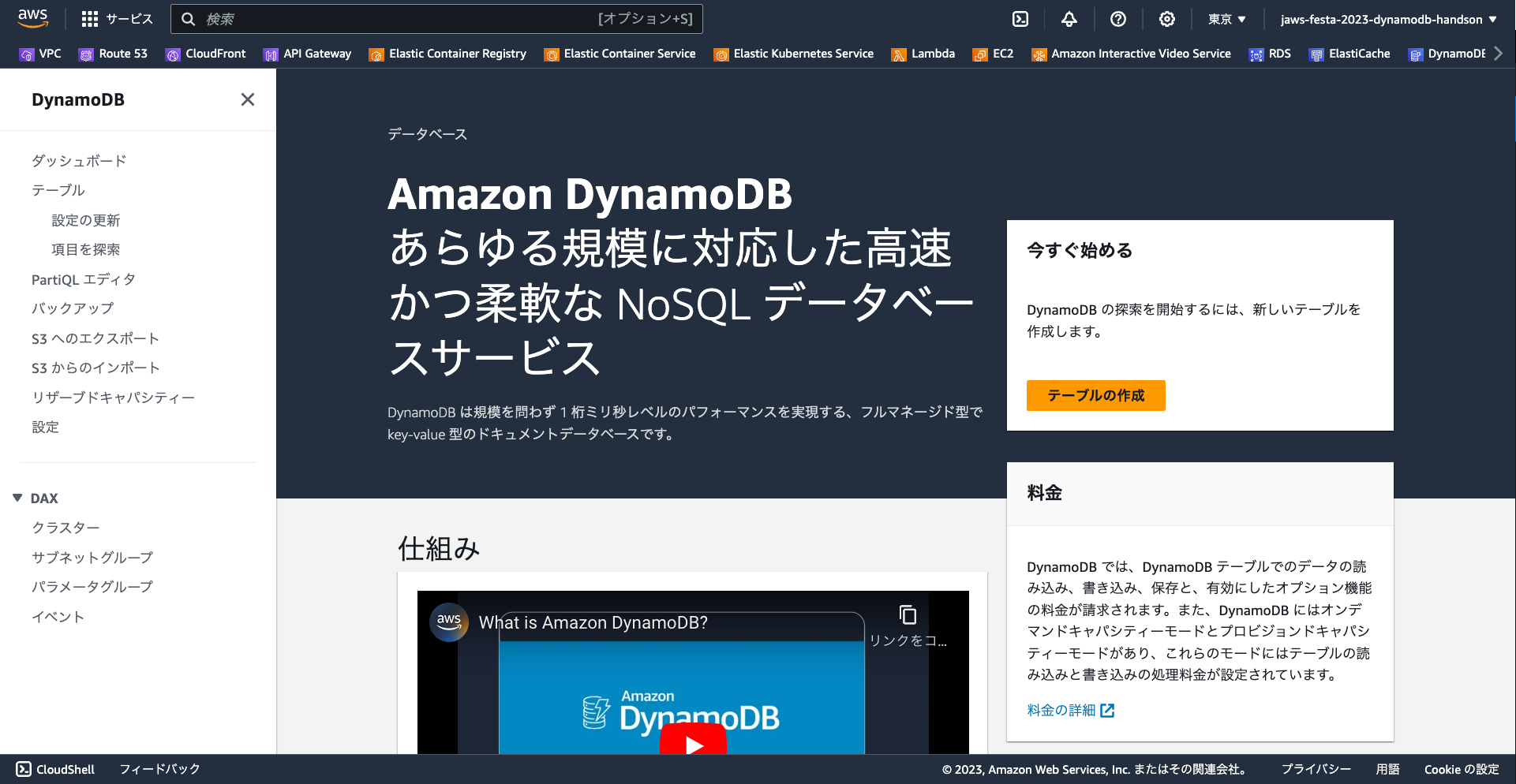
トップページには座学編で説明した内容が書かれています。
2-2-1. 【余談】AWS サービスのブックマークの仕方
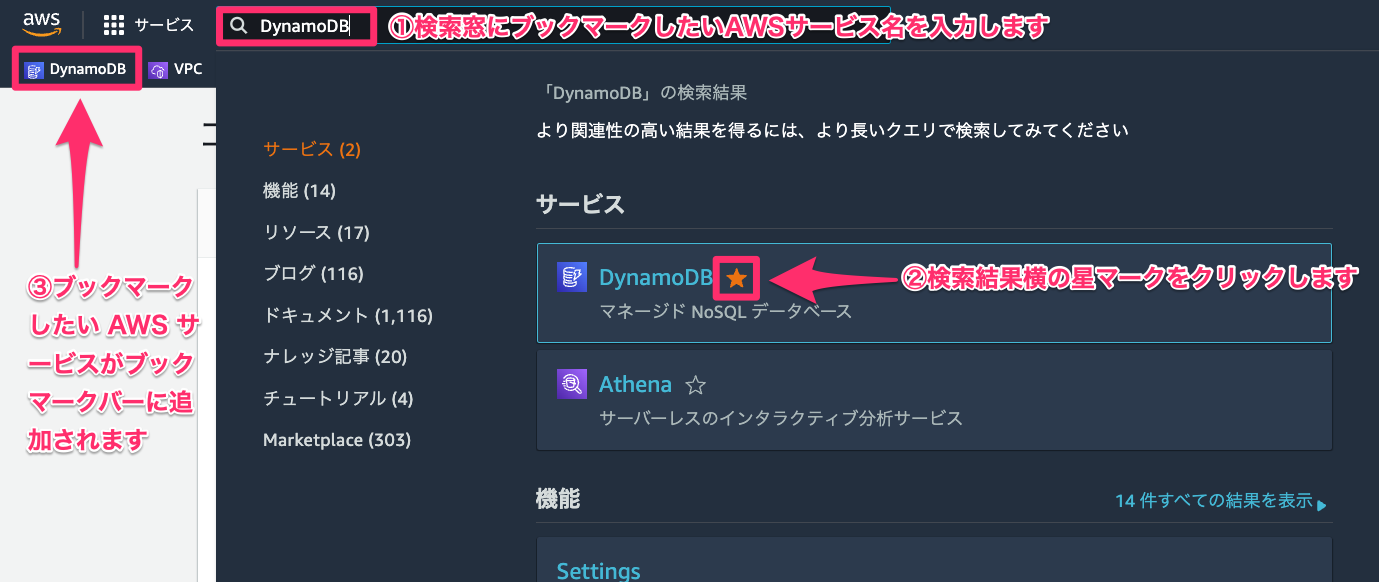
- 検索窓にブックマークしたい AWS サービス名(例では「DynamoDB」)を入力します。
- 検索結果横の星マークをクリックします。
- ブックマークしたい AWS サービスがブックマークバーに追加されます。
2-3. テーブルの作成
では早速、テーブルを作成していきましょう!
2-3-1. テーブル一覧を表示する
- DynamoDB サービスページの左にあるメニュー内の「テーブル」をクリックします。
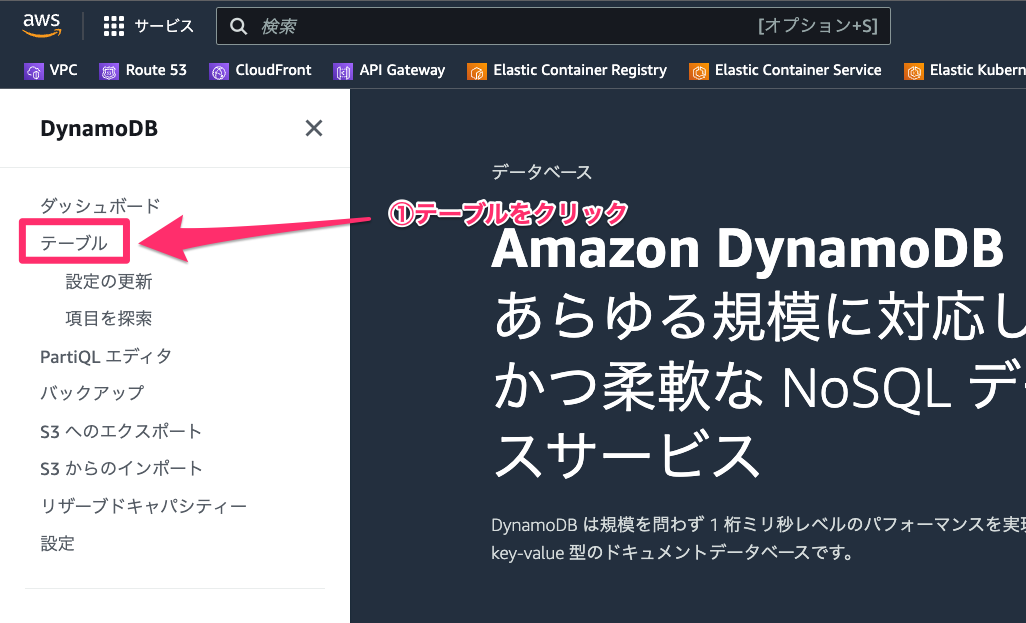
- そうすることでテーブル一覧を表示することができます。
2-3-2. テーブルを作成する (1/5)
書棚を管理するためのテーブルを作成していきます。
- 「テーブルの作成」をクリックします。
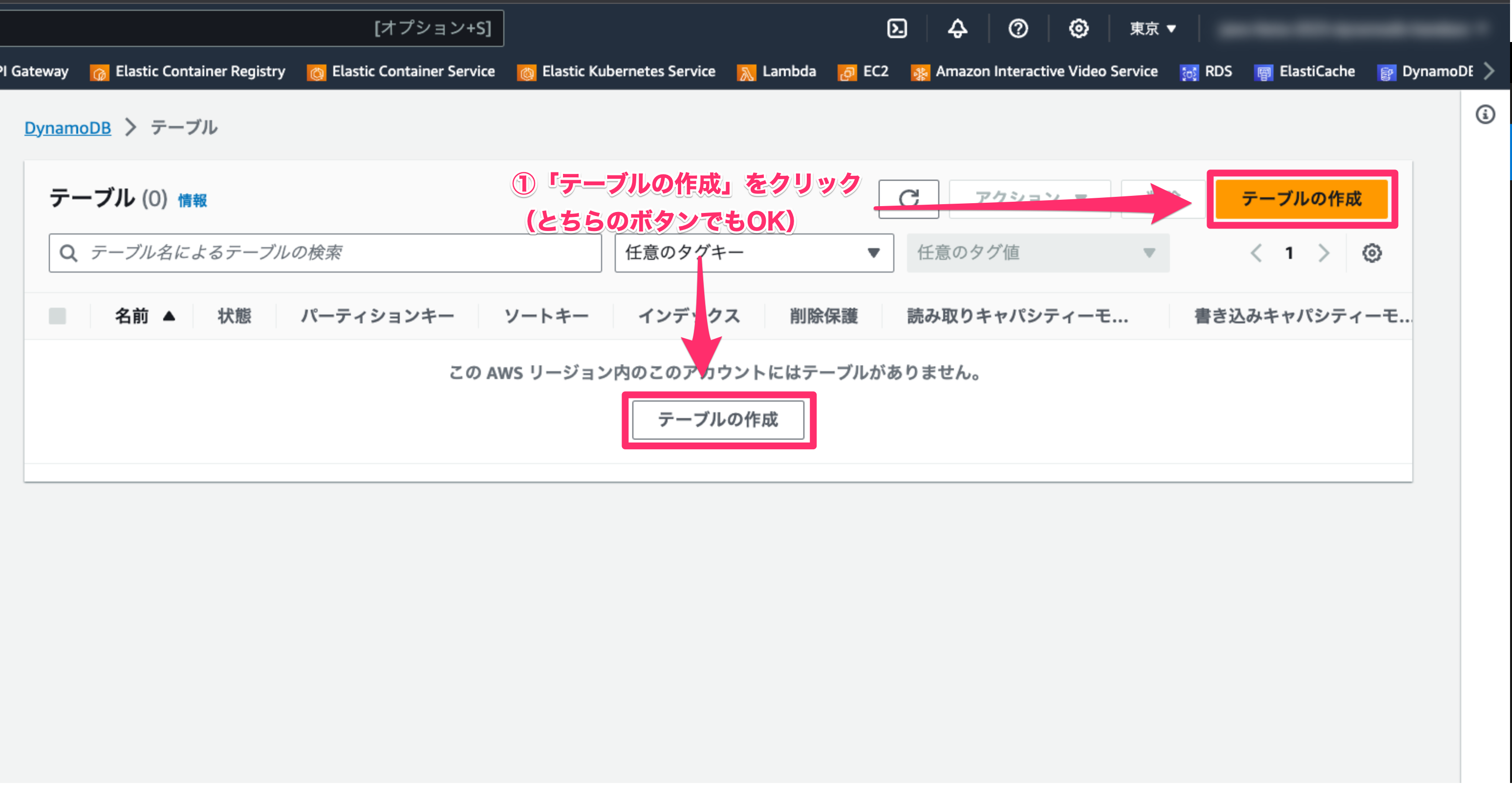
2-3-2. テーブルを作成する (2/5)
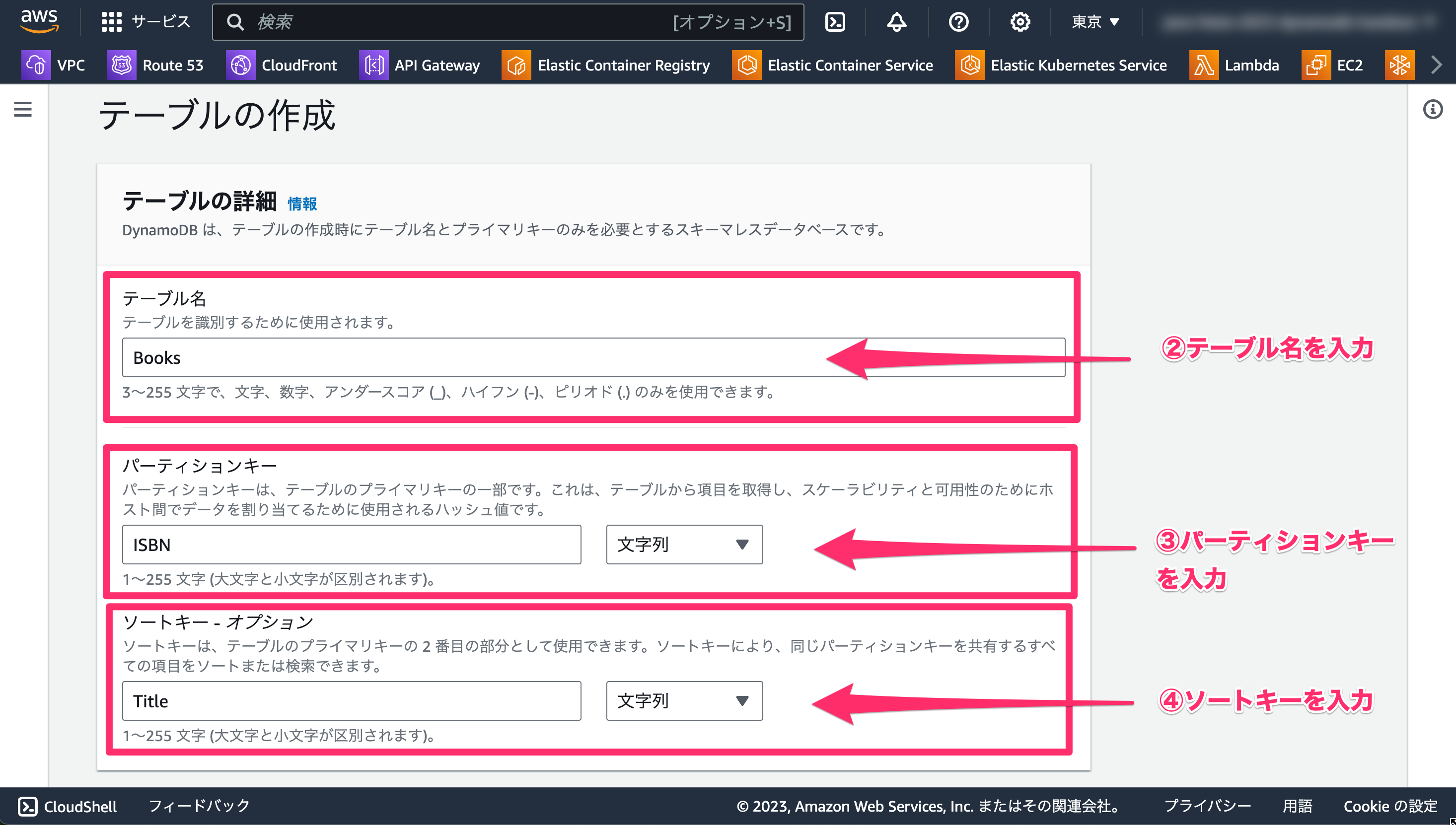
以下の内容を入力します。
- 「テーブル名」に「
Books」と入力します。 - 「主キー」に「
ISBN」と入力します。 - 「ソートキー」に「
Title」と入力します。
ISBN(アイエスビーエヌ)は、International Standard Book Number の略称(頭字語)。図書(書籍)および資料の識別用に設けられた国際規格コード(番号システム)の一種
引用:Wikipedia「ISBN」
2-3-2. テーブルを作成する (3/5)
2-3-2. テーブルを作成する (4/5)
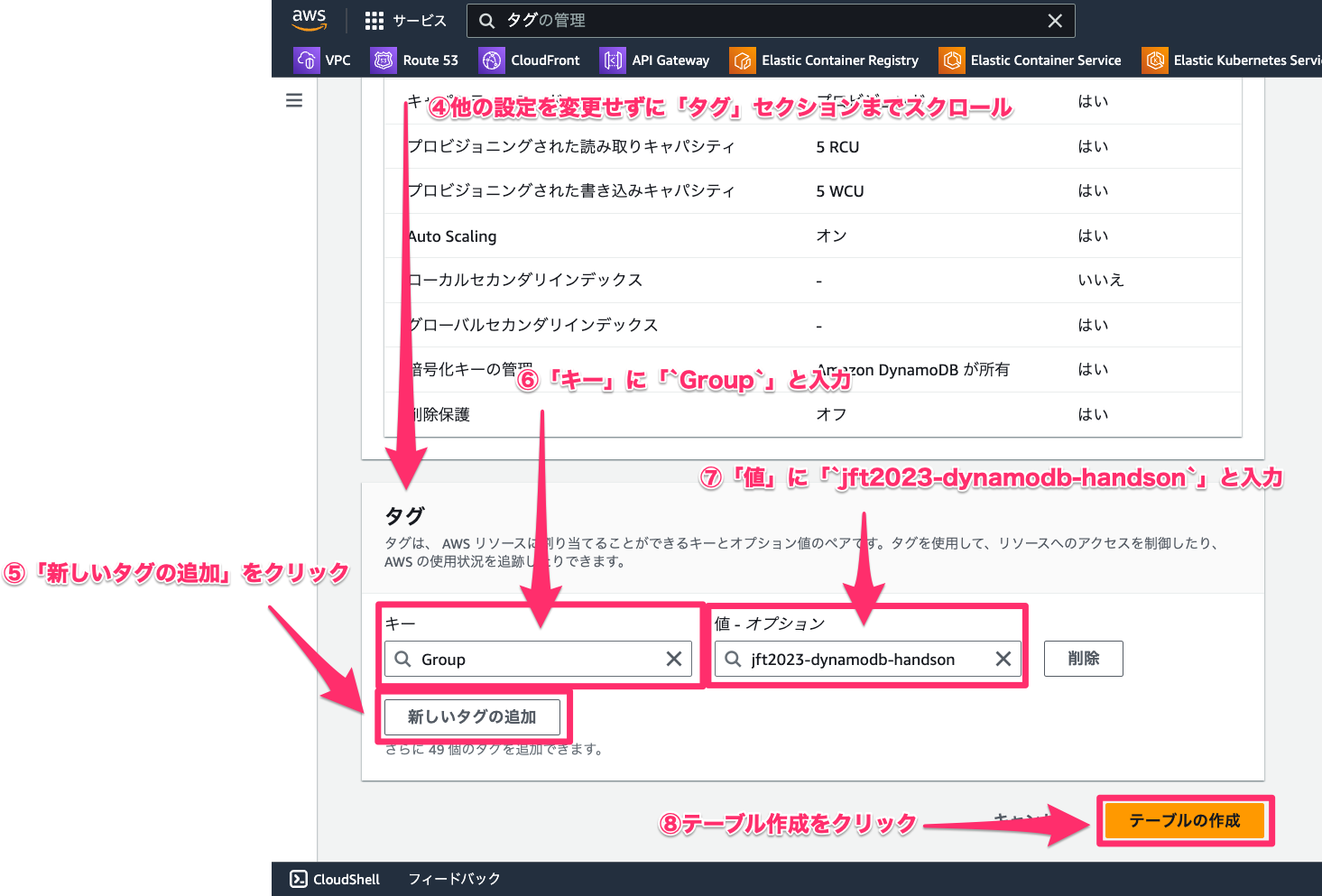
- 他の設定を変更せずに一番下までスクロールします。
- タグセクションの「新しいタグの追加」をクリックします。
- 「キー」に「
Group」と入力します。 - 「値」に「
jft2023-dynamodb-handson」と入力します。 - 「テーブルの作成」をクリックします。
2-3-2. テーブルを作成する (5/5)
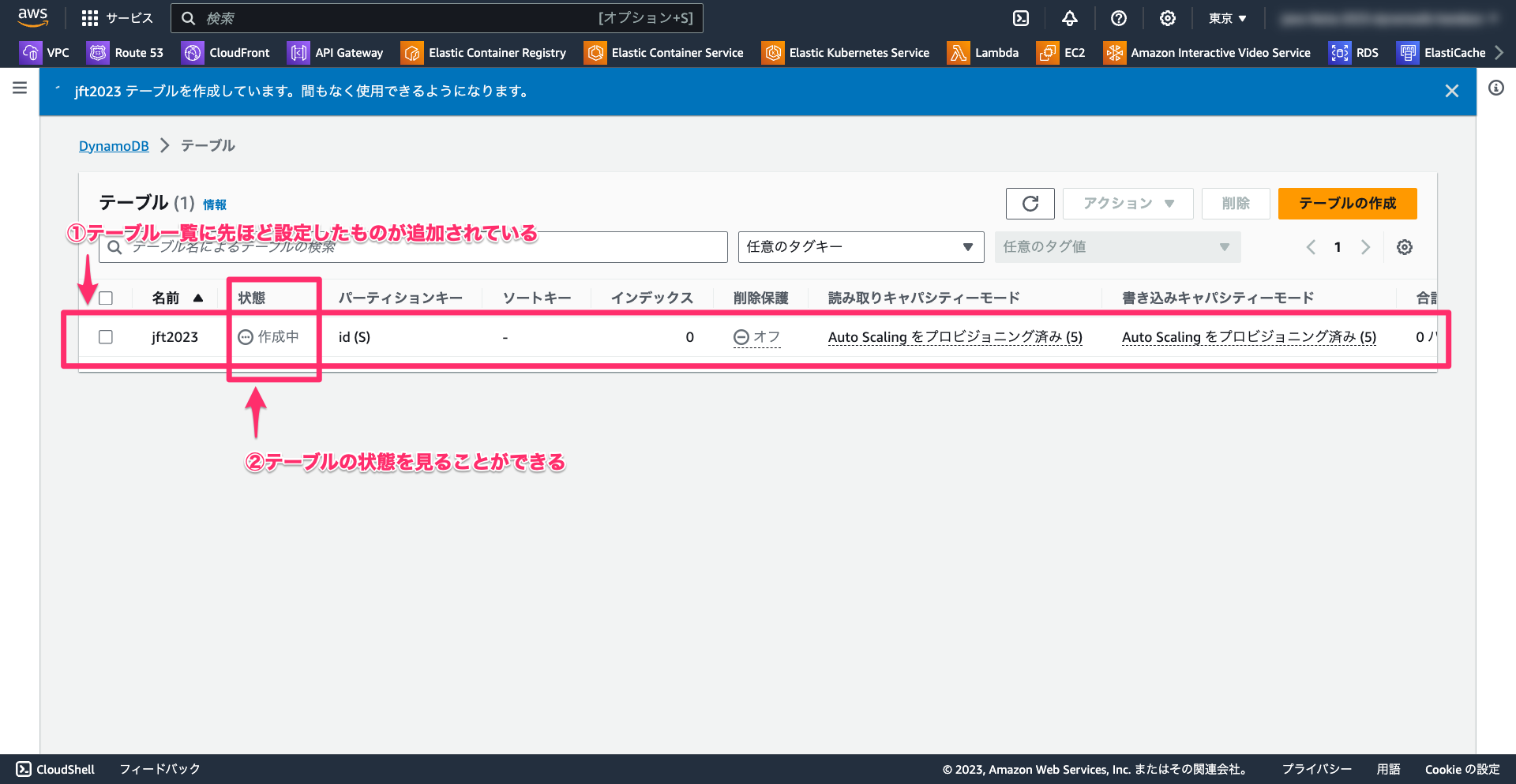
2-3-3. テーブルの作成状況を確認する
「テーブルの作成」をクリックするとテーブル一覧が表示され、自動的に作成処理が開始されます。テーブルの作成にはしばらく時間がかかりますが、テーブルが作成中かどうかの状態などを一覧から確認できます。通常、1 分程度で完了します。
2-3-4. テーブルの作成完了を確認する
作成が完了すると以下のような画面になります。
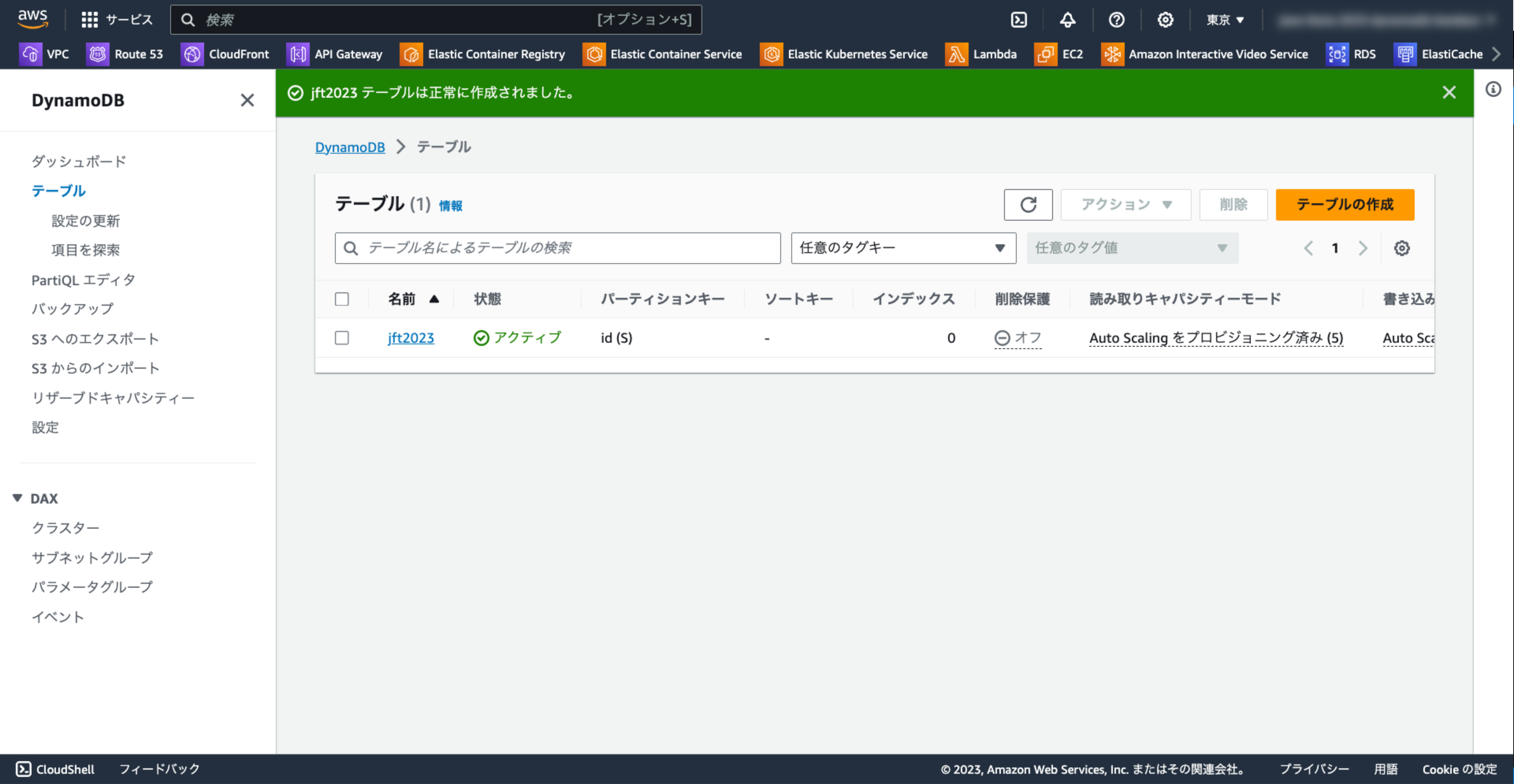
テーブルを作成できました!🎉
2-5-1. 項目の作成
それでは最初の項目を追加してみましょう。
- 先ほど作成したテーブルの名前をクリックします。
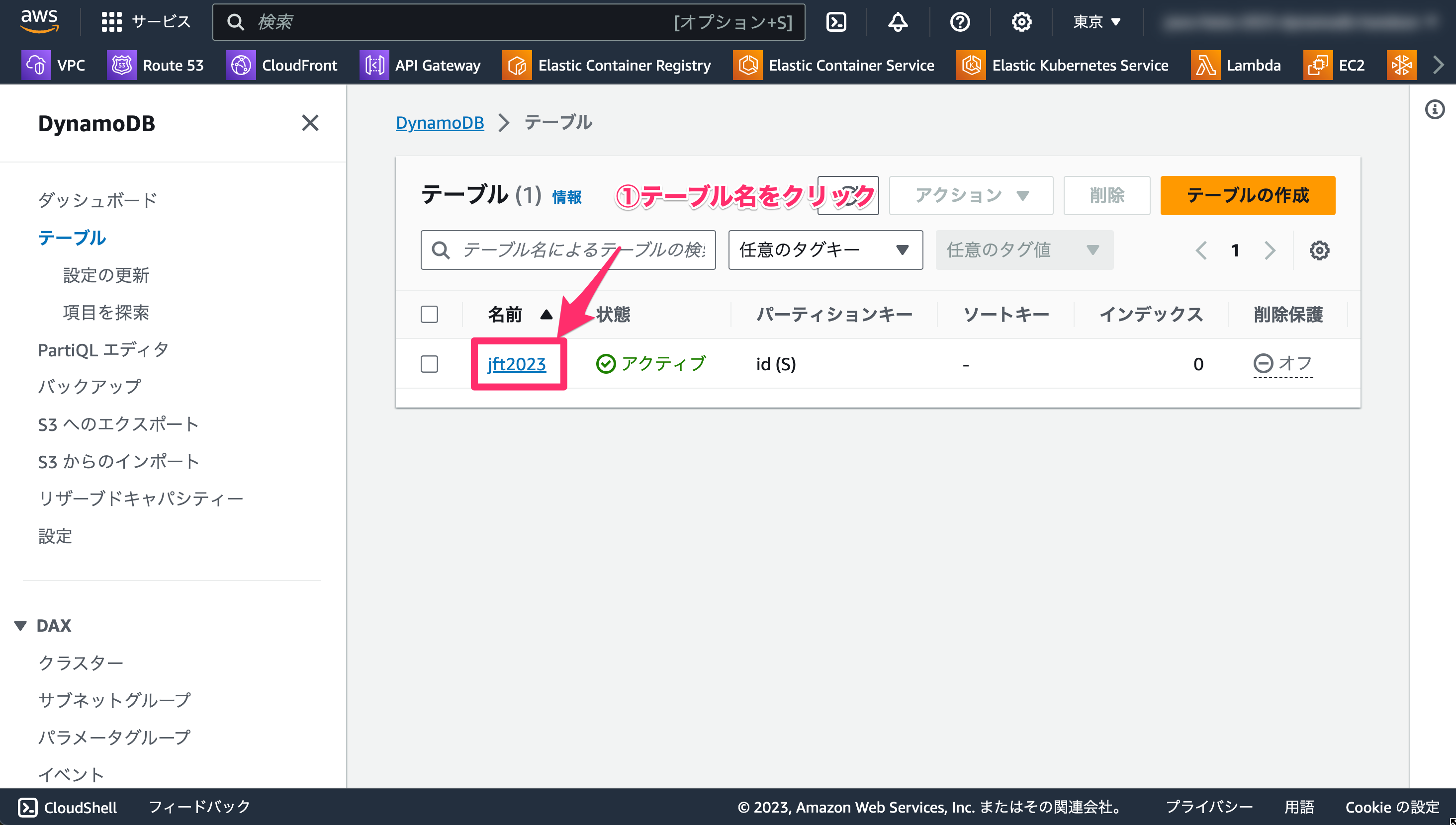
- 「テーブルアイテムの探索」をクリックします。
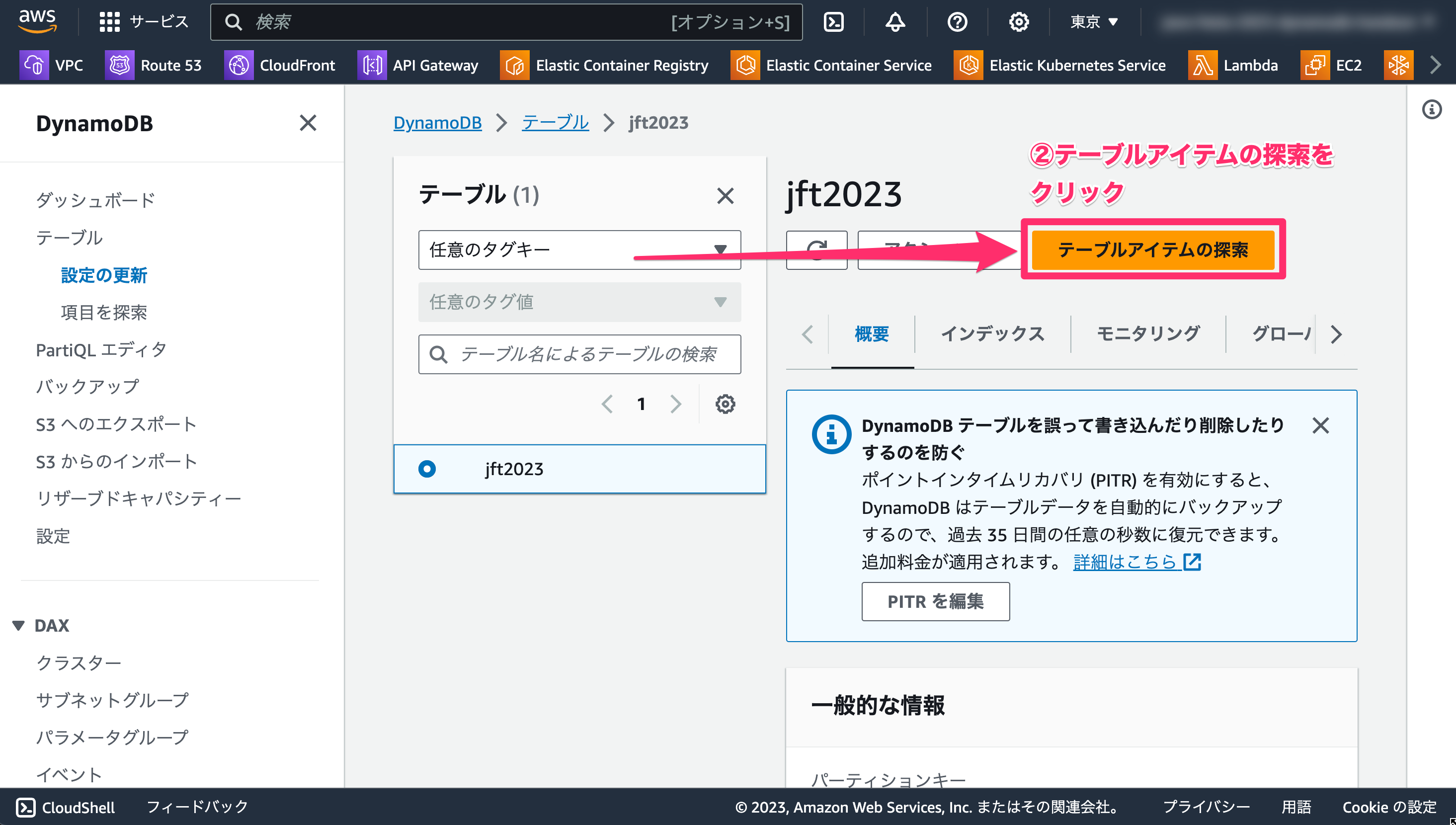
- 下にスクロールして、「項目を作成」をクリックします。
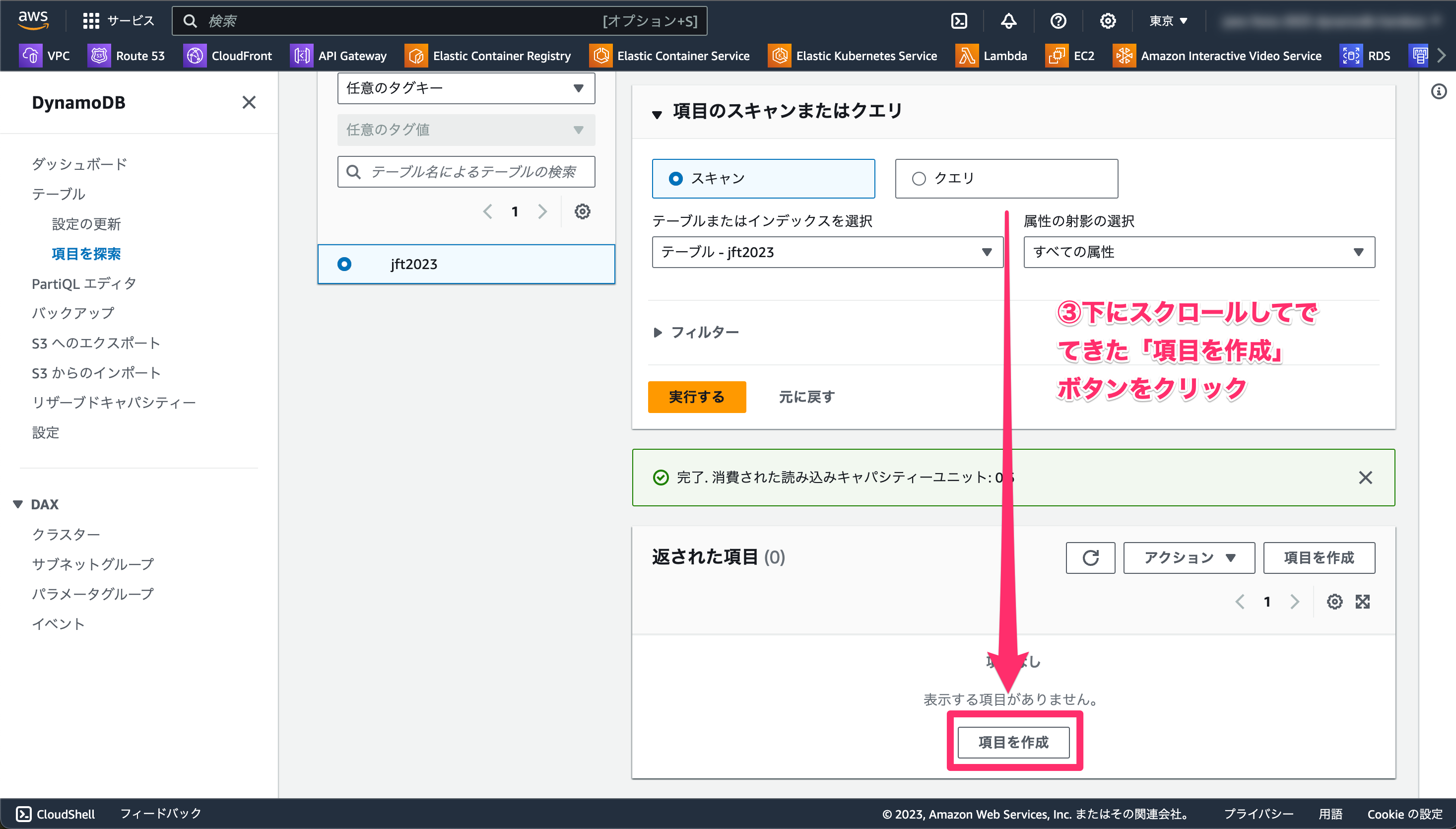
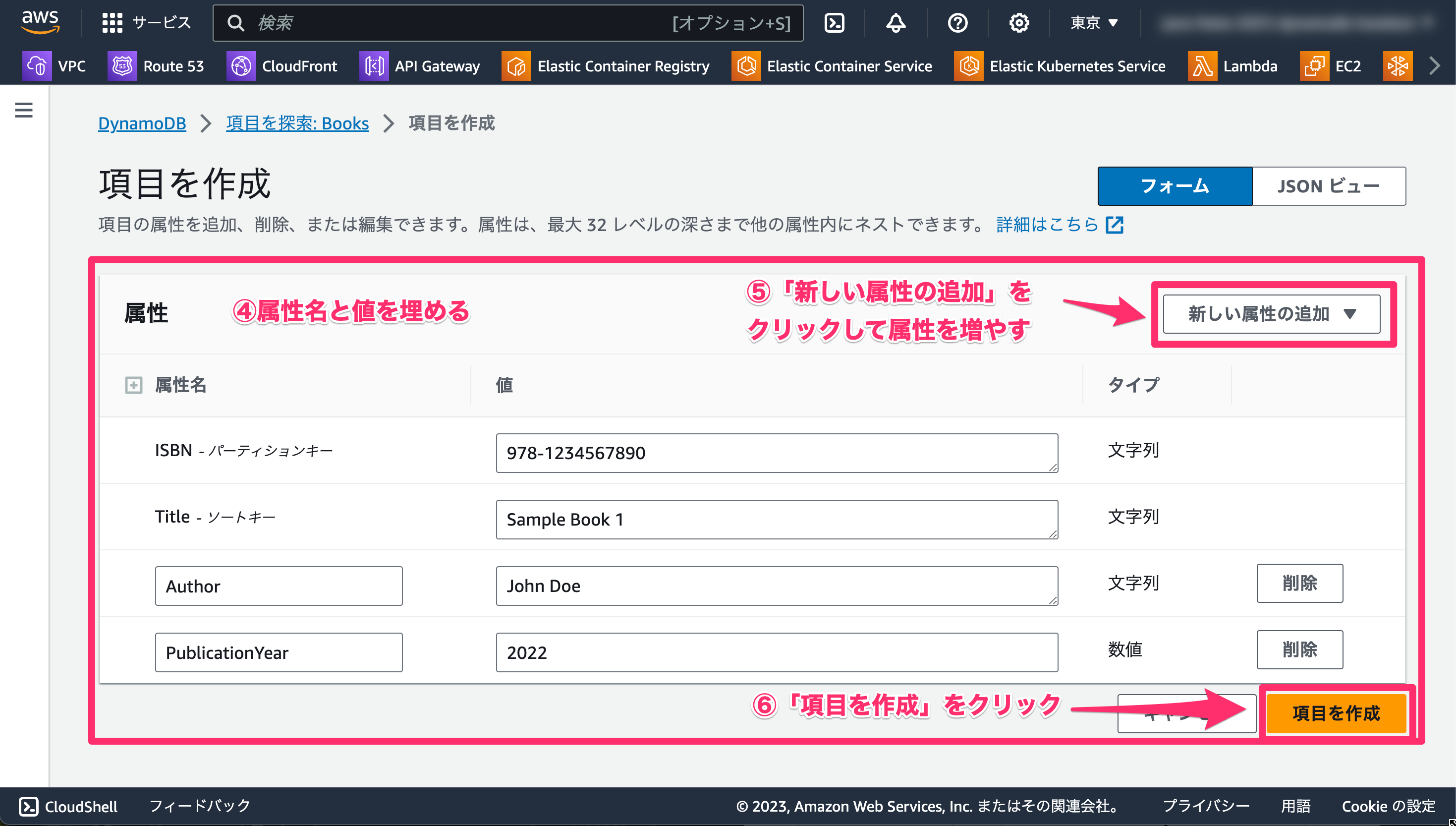
- 属性名と値を埋めていきます。内容は以下の通りです。
- 「
ISBN」に「978-1234567890」と入力します。 - 「
Title」に「Sample Book 1」と入力します。
- 「
- 「新しい属性の追加」を押して、以下の内容を入力します。
- 文字列を追加して属性名に「
Author」、値に「John Doe」と入力します。 - 数値を追加して属性名に「
PublicationYear」値に「2022」と入力します。
- 文字列を追加して属性名に「
- 「項目を作成」をクリックします。
項目が追加されました!🎉
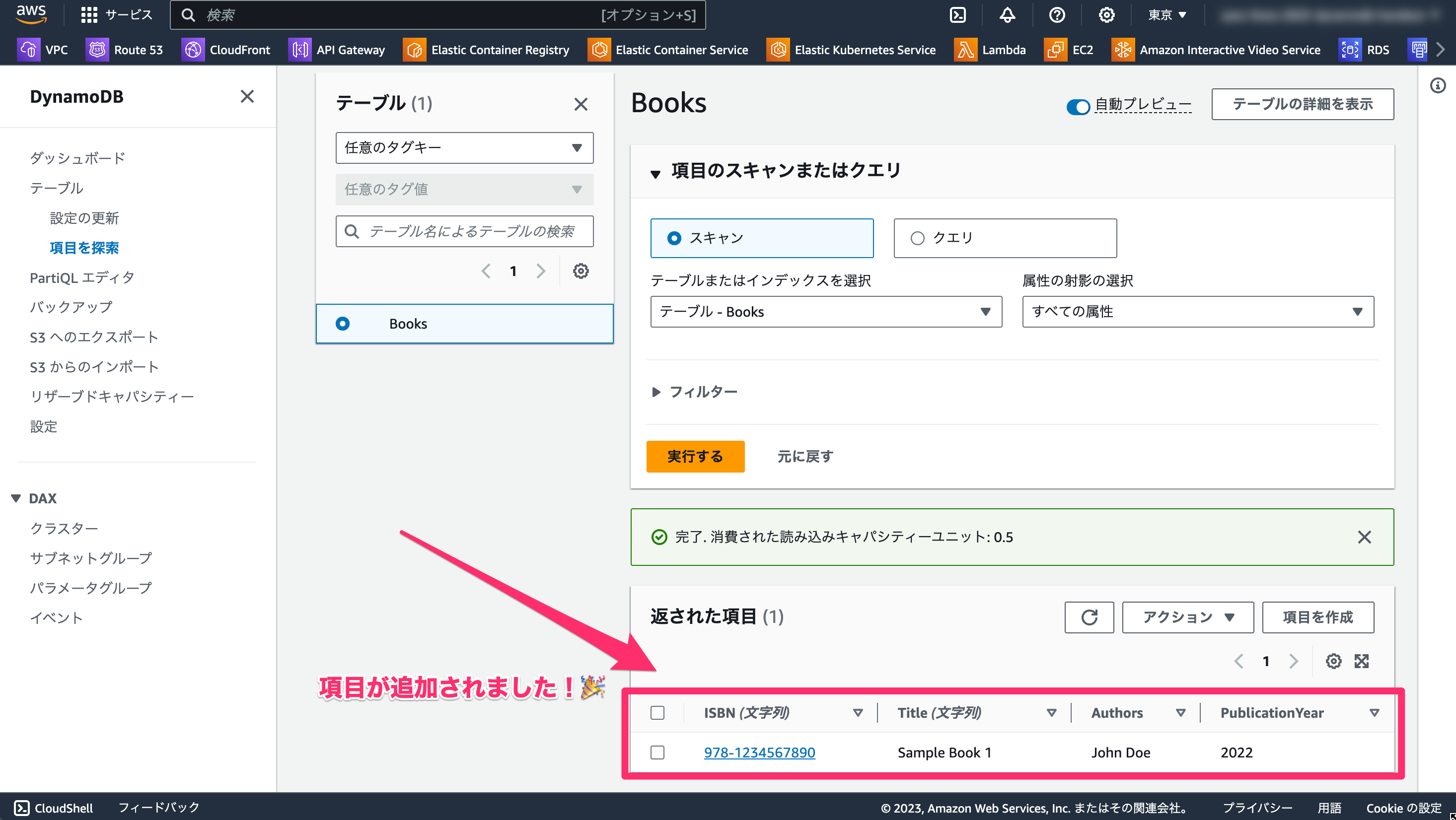
参考:https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/getting-started-step-2.html
もう 1 つ項目を追加してみましょう。
- 「項目を作成」をクリックします。
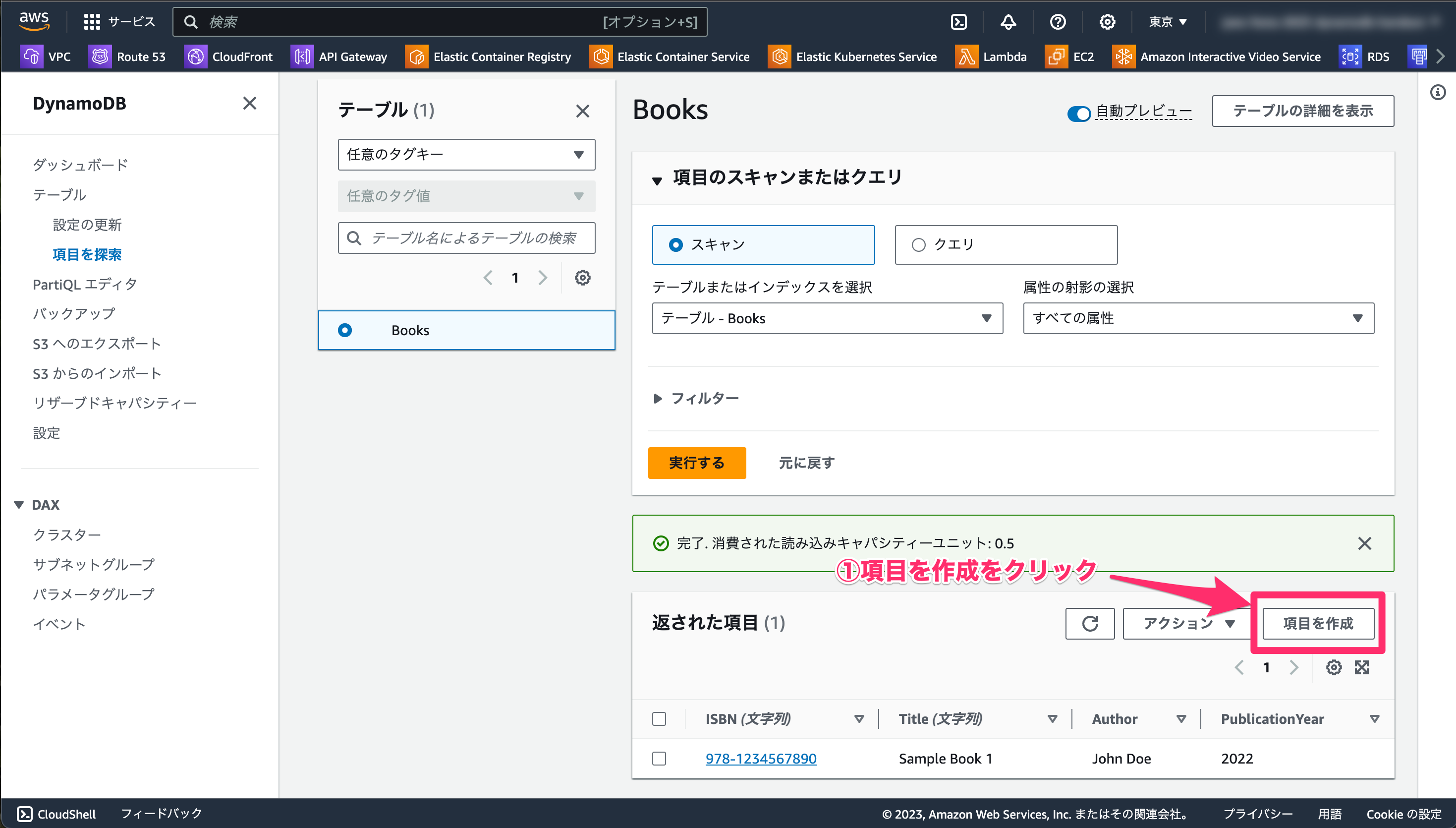
先ほどはフォームに入力しましたが、今度は DynamoDB JSON を入力してみます。
- 「JSON ビュー」をクリックします。
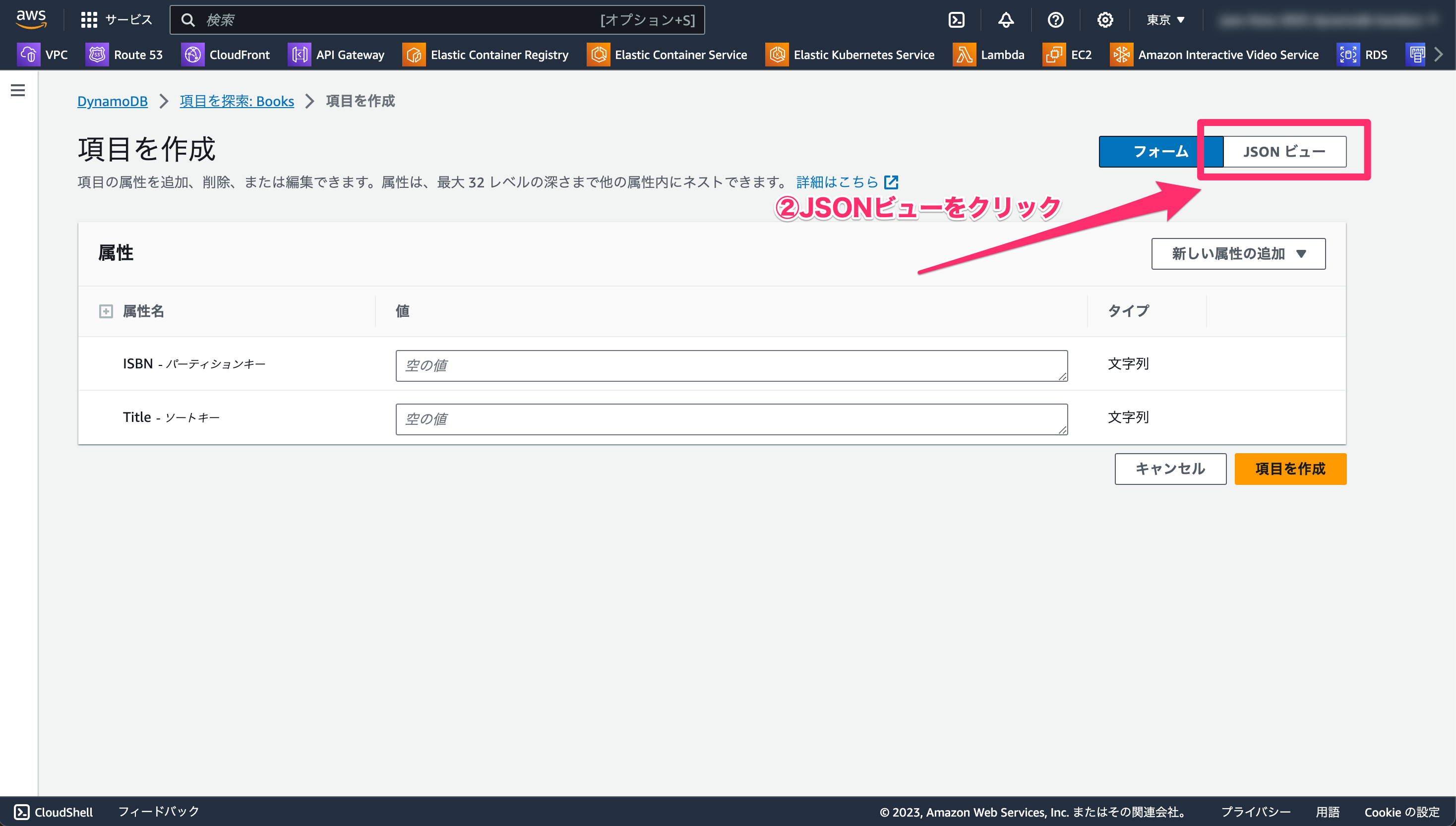
- 以下をコピーします。
{
"ISBN": { "S": "978-0987654321" },
"Title": { "S": "Sample Book 2" },
"Author": { "S": "Jane Smith" },
"PublicationYear": { "N": "2023" }
}
- 「JSON ビュー」に貼り付けます。
- 「項目を作成」をクリックします。
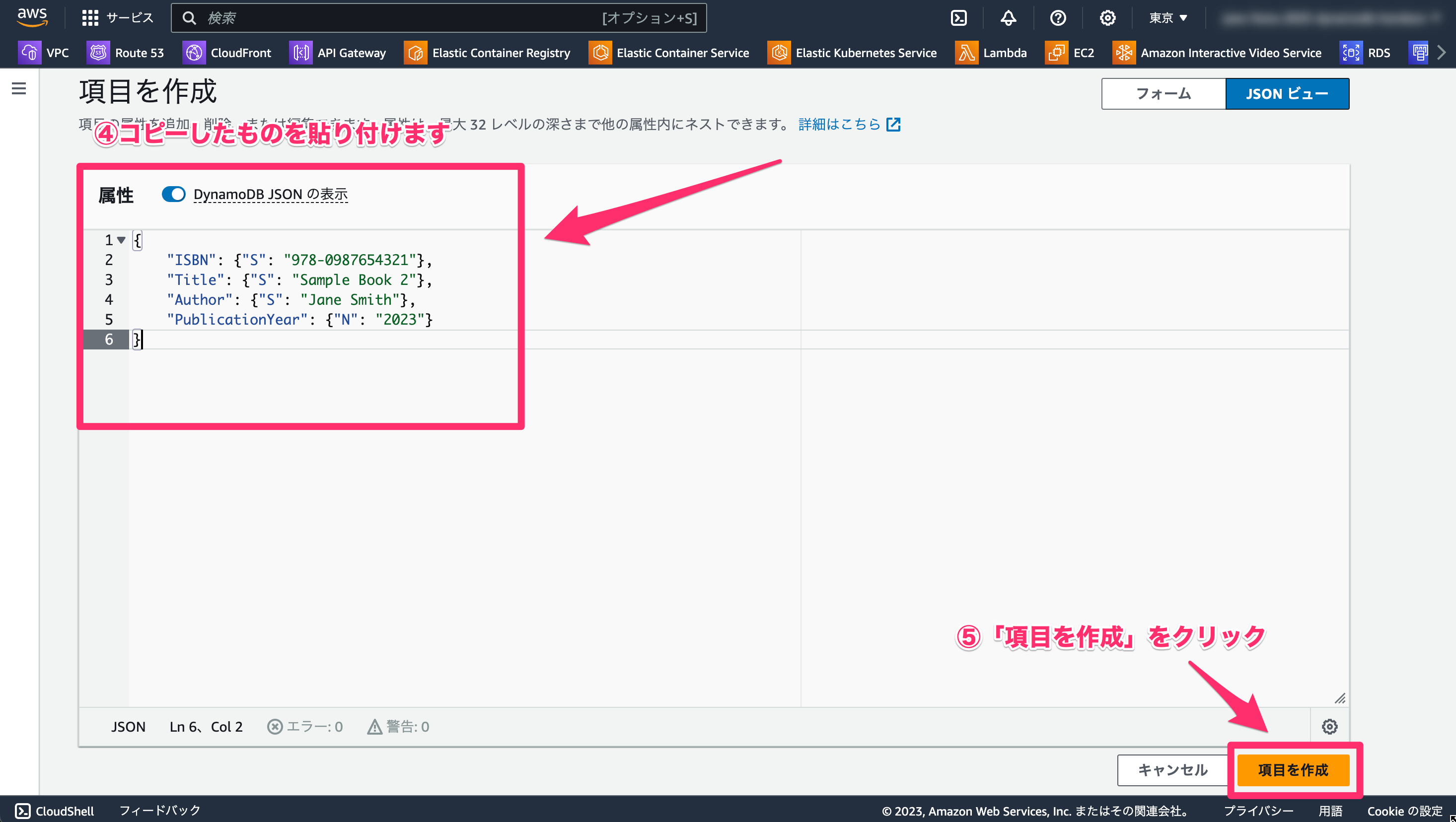
【余談】JSON でも項目を作成できる
DynamoDB では、JSON を使用して項目を作成することもできます。
JSON ビューにした際に「DynamoDB JSON の表示」トグルをクリックしてオフにすると、生の JSON を編集することができます。例えば以下のような JSON を入力して項目を作成することができます。
{
"ISBN": { "S": "978-1111222233" },
"Title": { "S": "Sample Book 3" },
"Author": { "S": "Alice Brown" },
"PublicationYear": { "N": "2020" }
}
余裕があれば試してみてください。
2-5-2. 項目の検索
様々な方法で項目を検索してみましょう。
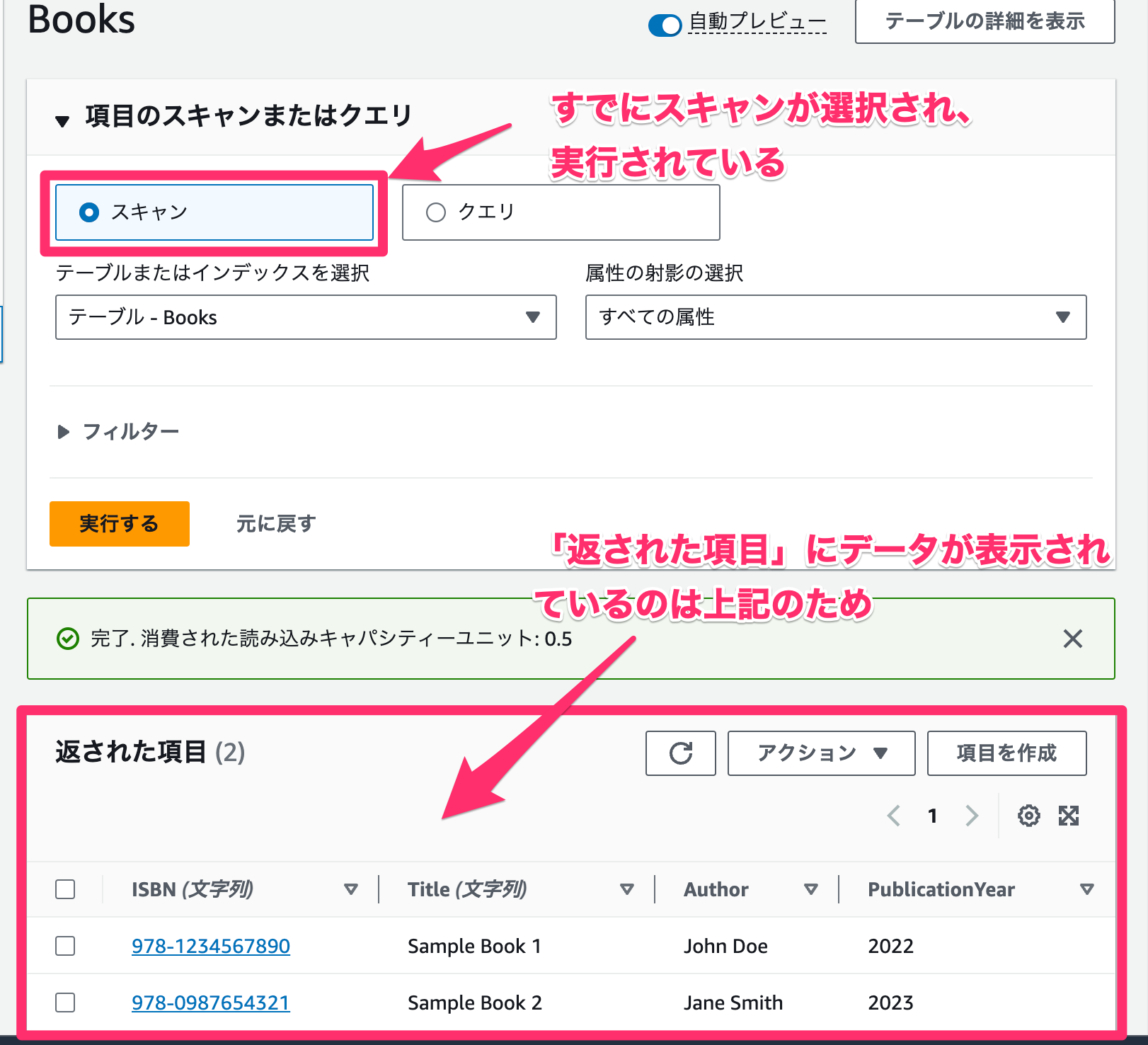
スキャン
全ての項目のデータ属性を返します。1 回のスキャンで最大 1 MB のデータを返すことができます。
実は項目作成後に見た「返された項目」はの内容はスキャンの結果です。
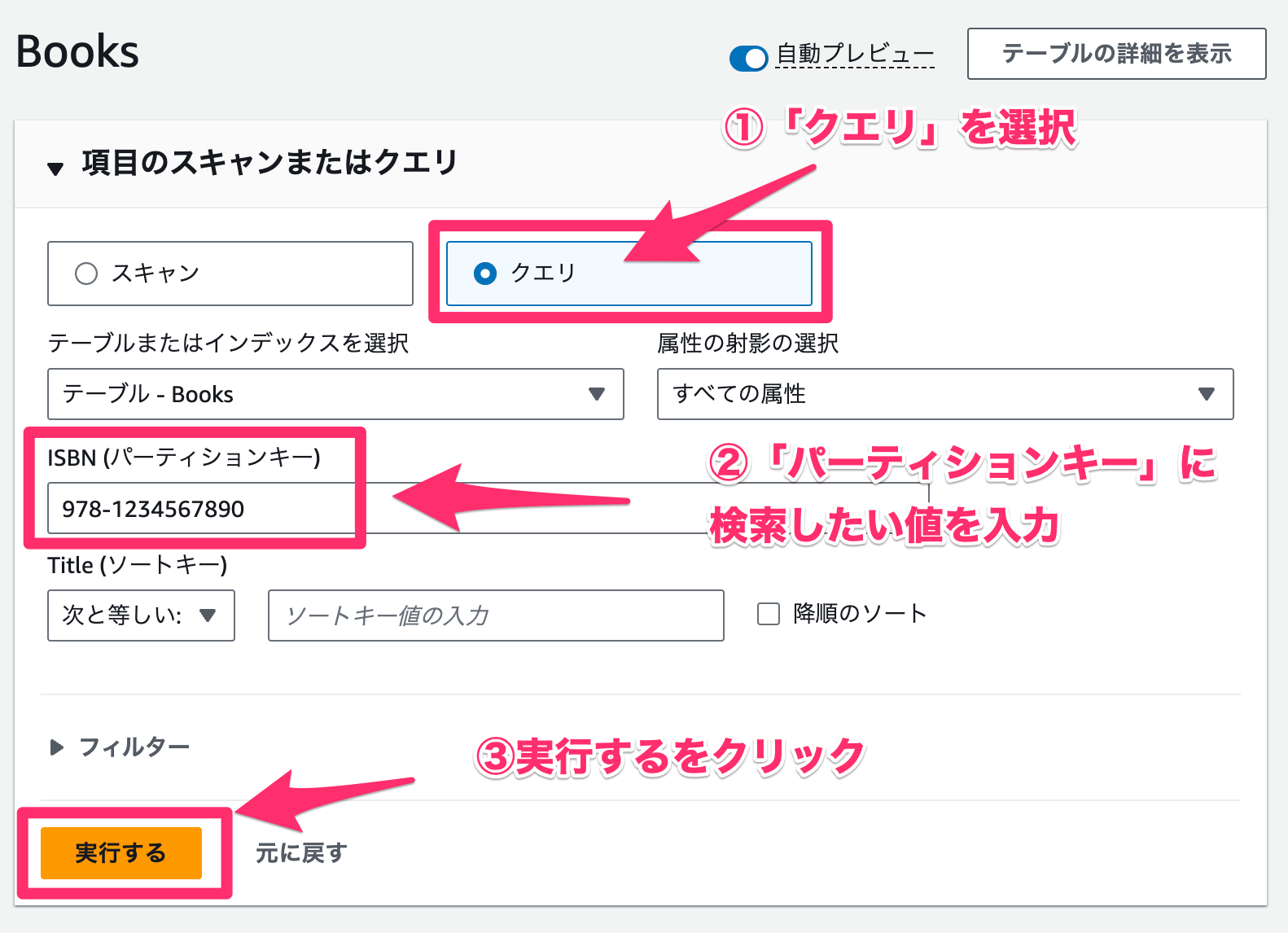
クエリ
テーブルまたはインデックス内の項目をクエリします。パーティションキーやソートキーを指定して検索することができます。
今回は ISBN が「978-1234567890」の項目を検索してみましょう。
- 「クエリ」を選択します。
- 「
ISBN」に「978-1234567890」と入力します。 - 「実行する」をクリックします。
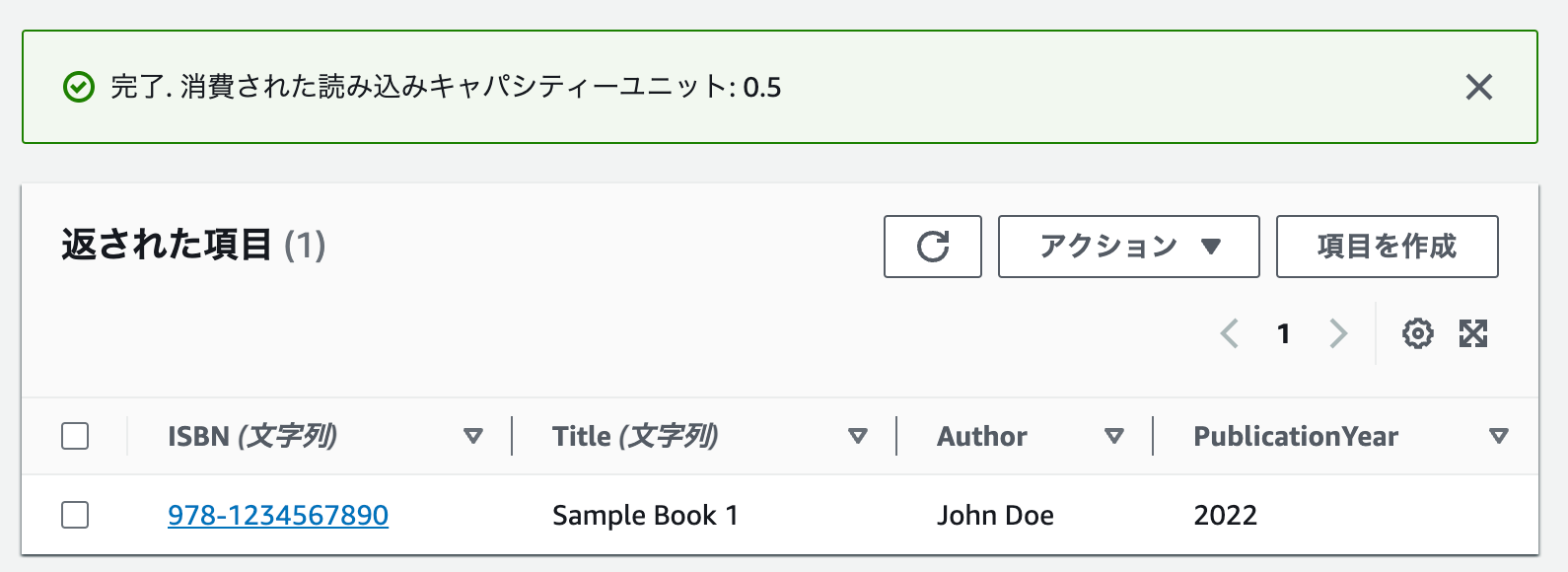
クエリできました!🎉
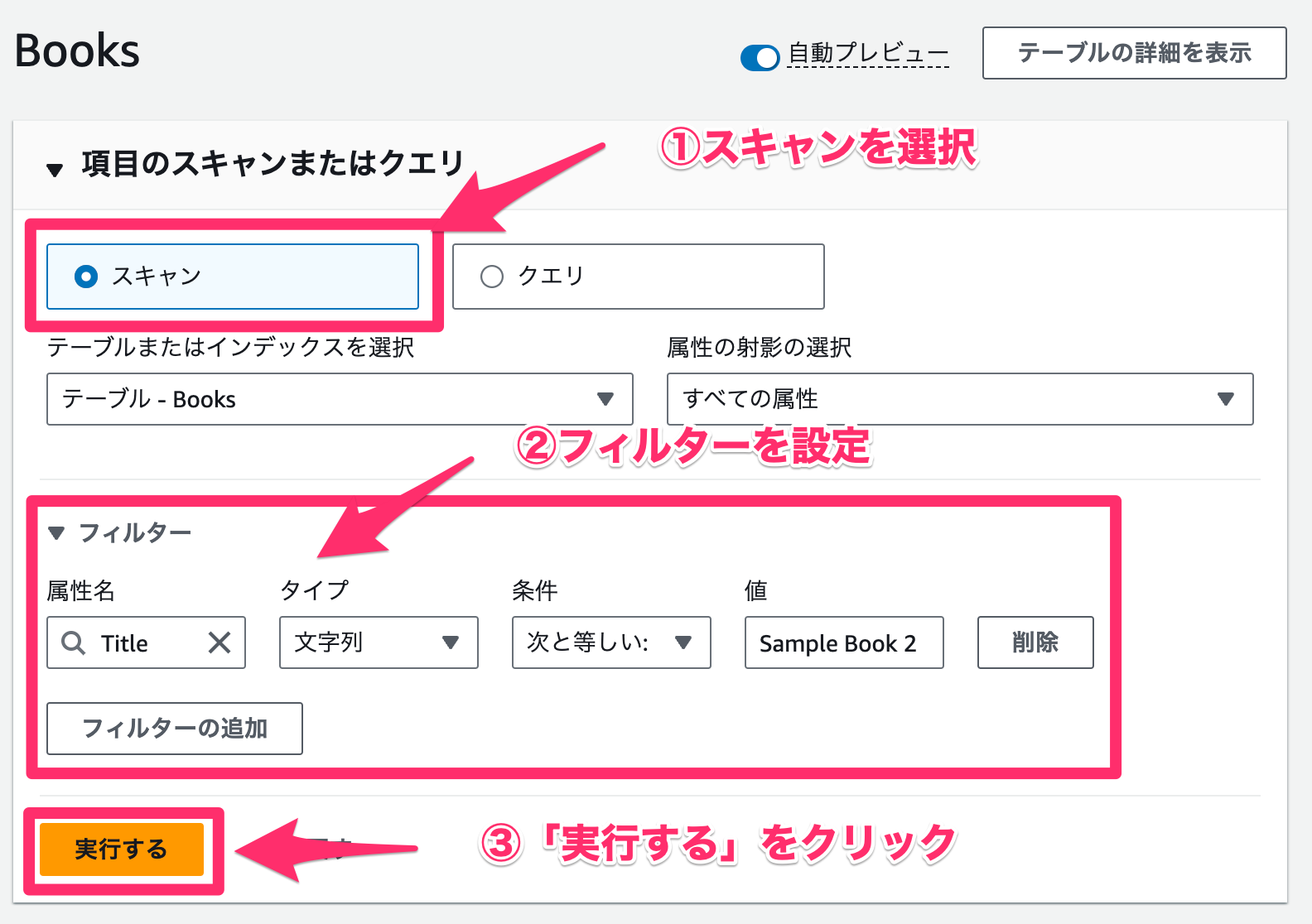
フィルタ
フィルター機能も試してみましょう。クエリと違い、フィルタはスキャンやクエリの後に行うことができます。
- スキャンを選択します。
- フィルターを以下の通りに設定します。
- 属性名を「
Title」に - タイプを「
文字列」に - 条件を「
次と等しい:」に - 値を「
Sample Book 2」に
- 属性名を「
- 「実行する」をクリックします。
フィルタできました!🎉
2-5-3. 項目の操作
項目の操作をやってみましょう。
編集
任意の項目を編集してみます。
- パーティションキーの値をクリックします。
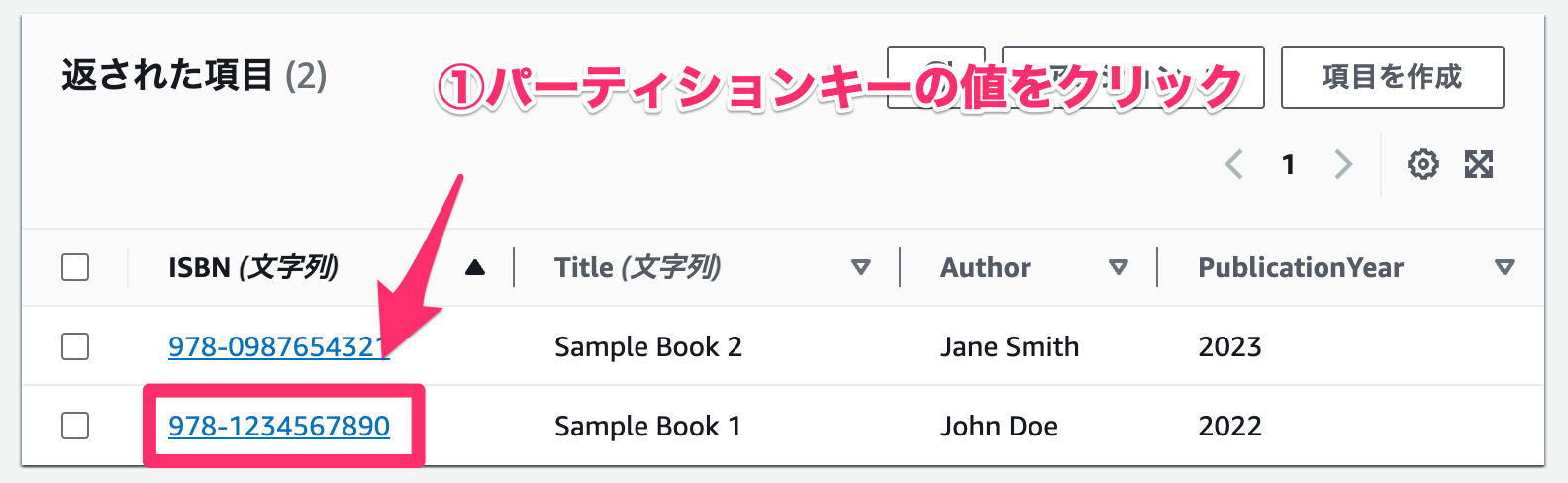
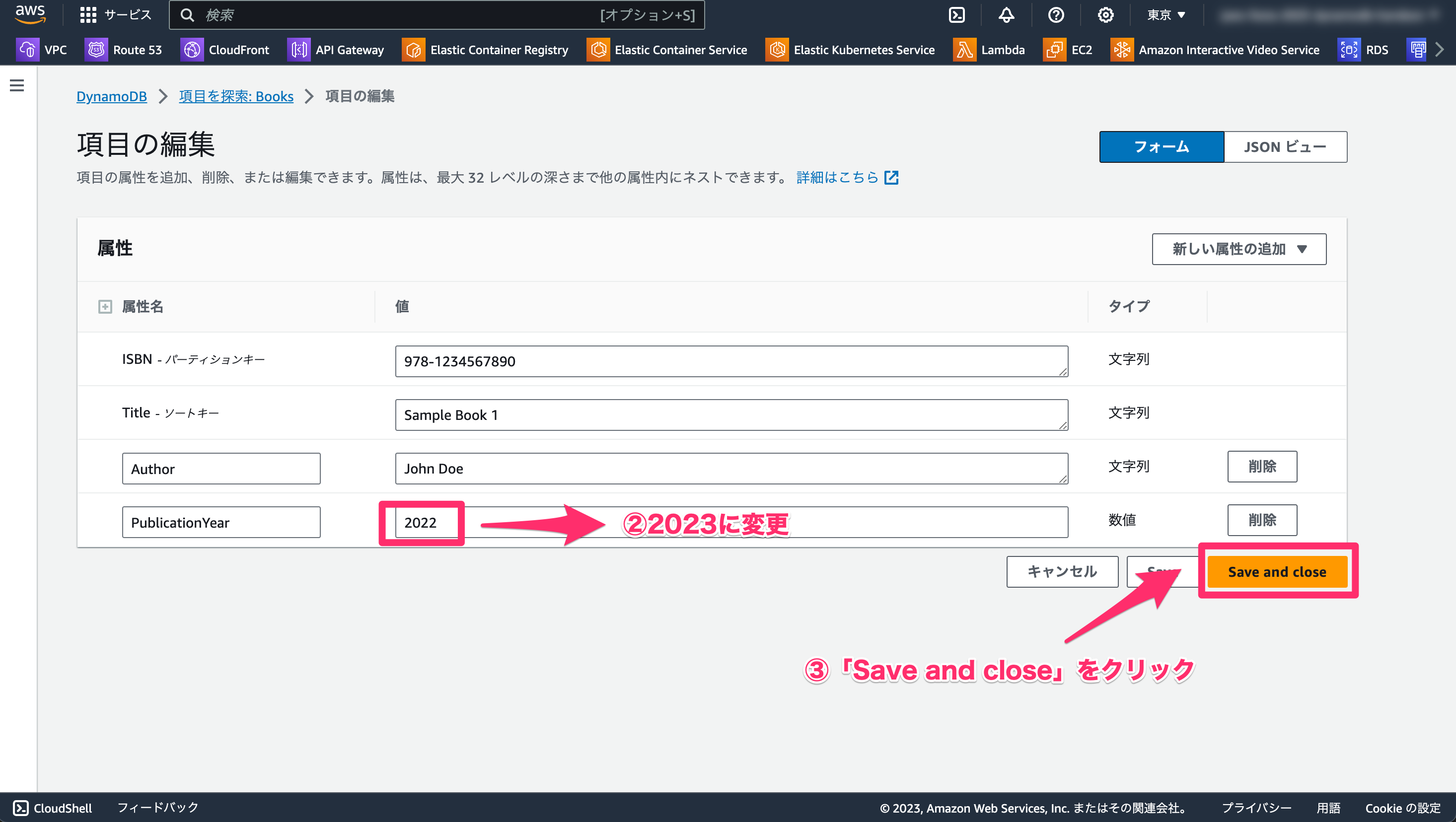
- 「
PublicationYear」を「2023」に変更します。 - 「Save and close」をクリックします。
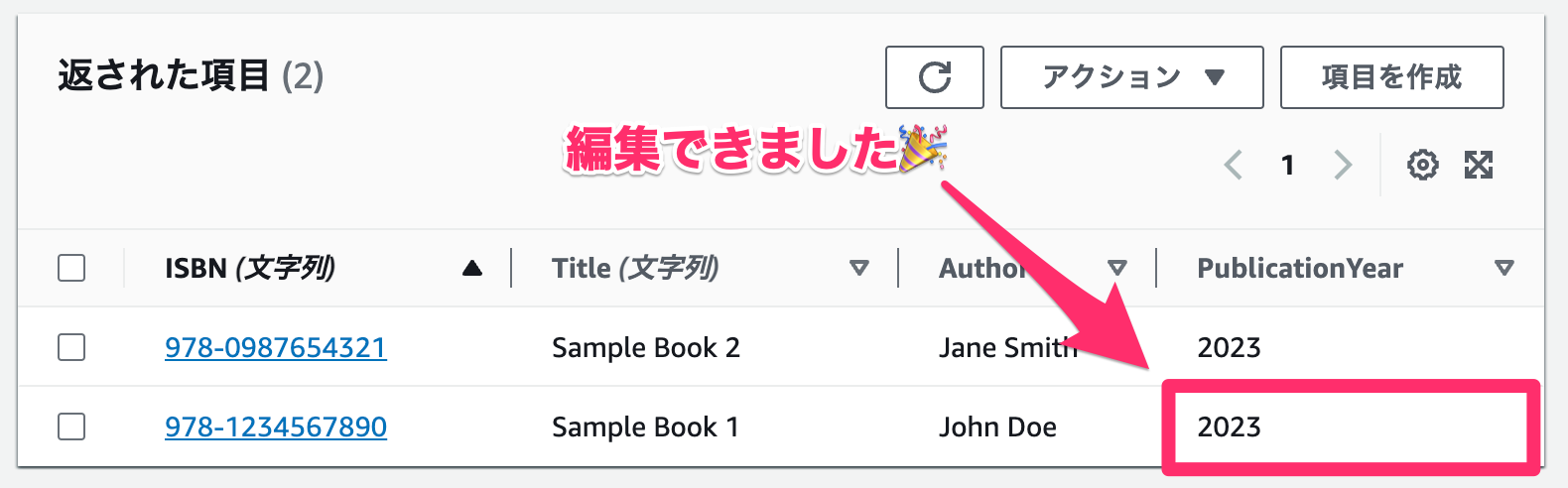
編集できました!🎉
複製
次に項目を複製してみます。
- 任意の項目を選択します。
- 「アクション」メニューから「項目の複製」をクリックします。
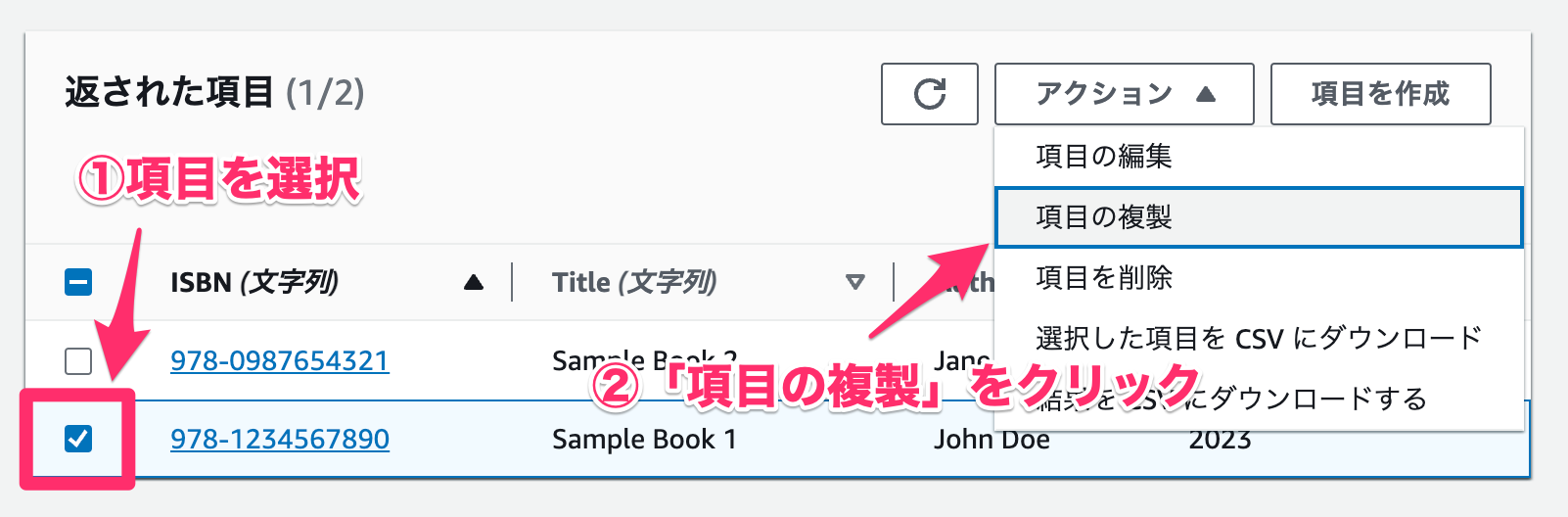
見慣れてきたフォームが表示されます。プライマリキーであるパーティションキーとソートキーの複合キーは一意である必要があるので変更する必要があります。
- 「
ISBN」を「978-1234567891」に変更します。 - 「
Title」を「Sample Book 1 Copy」に変更します。 - 「項目を作成」をクリックします。
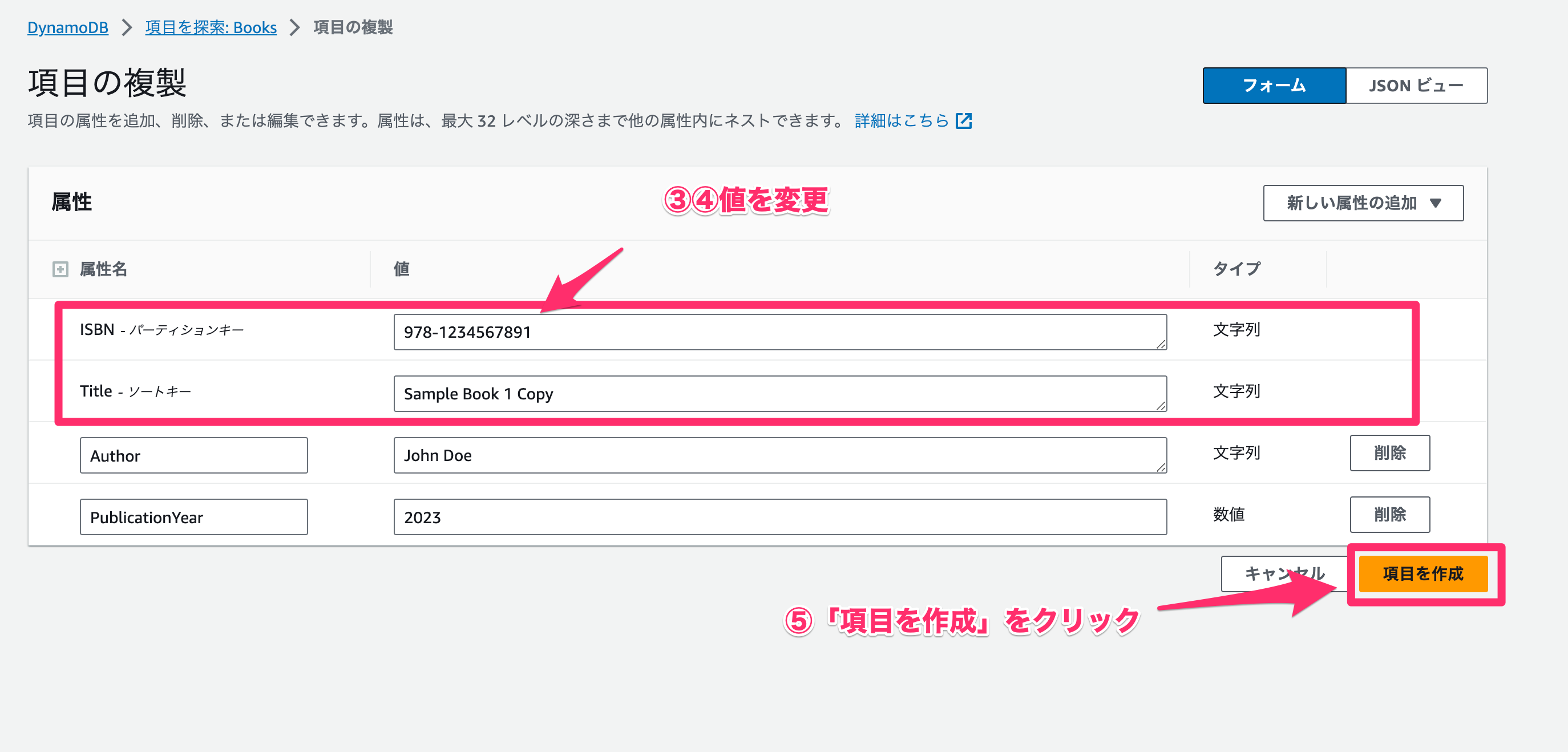
複製できました!🎉
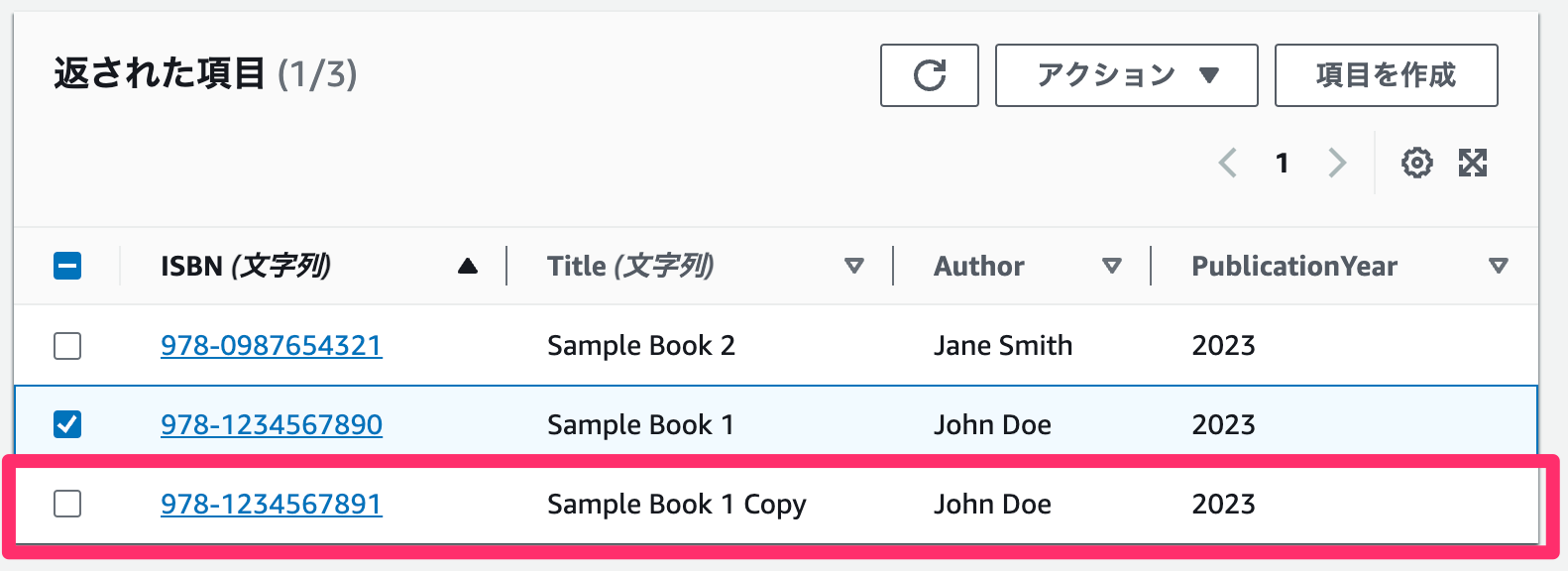
削除
最後に項目を削除してみます。
- 任意の項目を選択します。
- 「項目を削除」をクリックします。
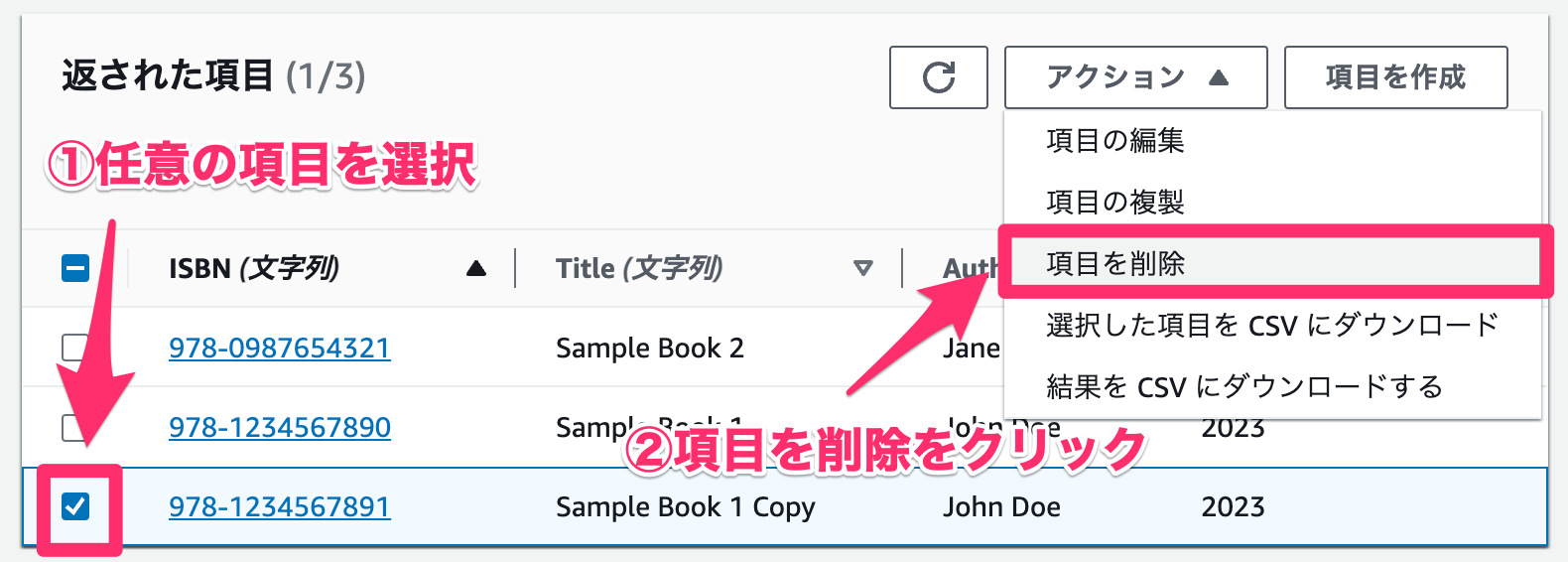
- 「削除」をクリックします。
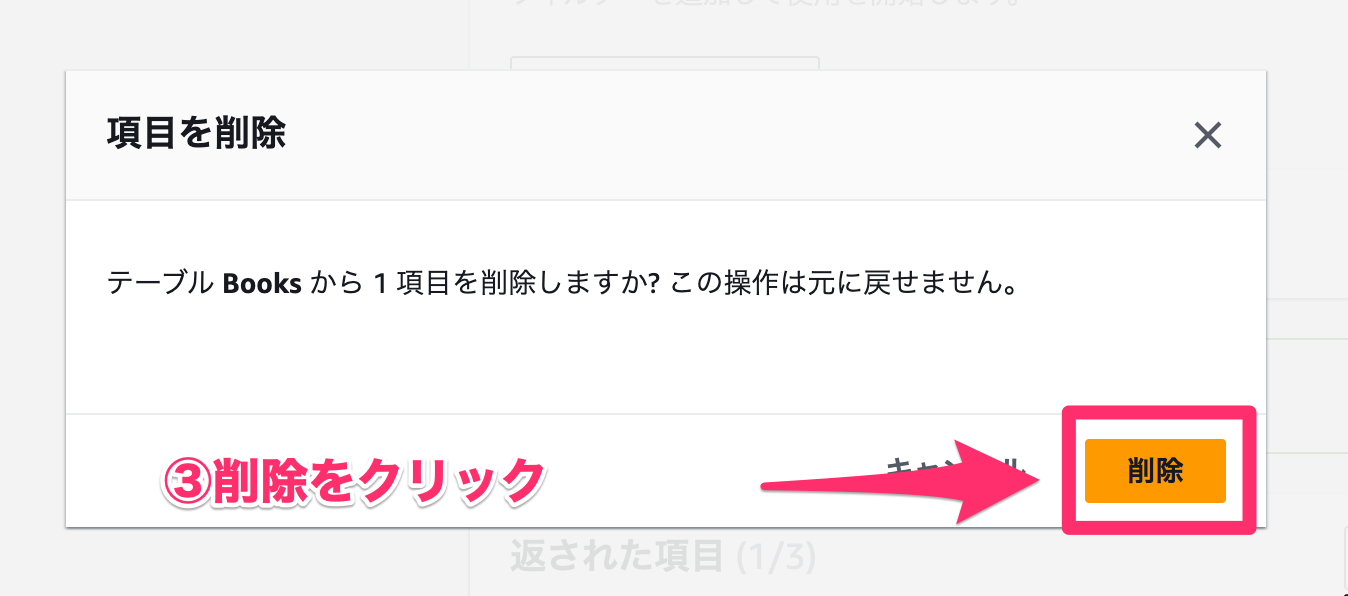
削除できました!🎉
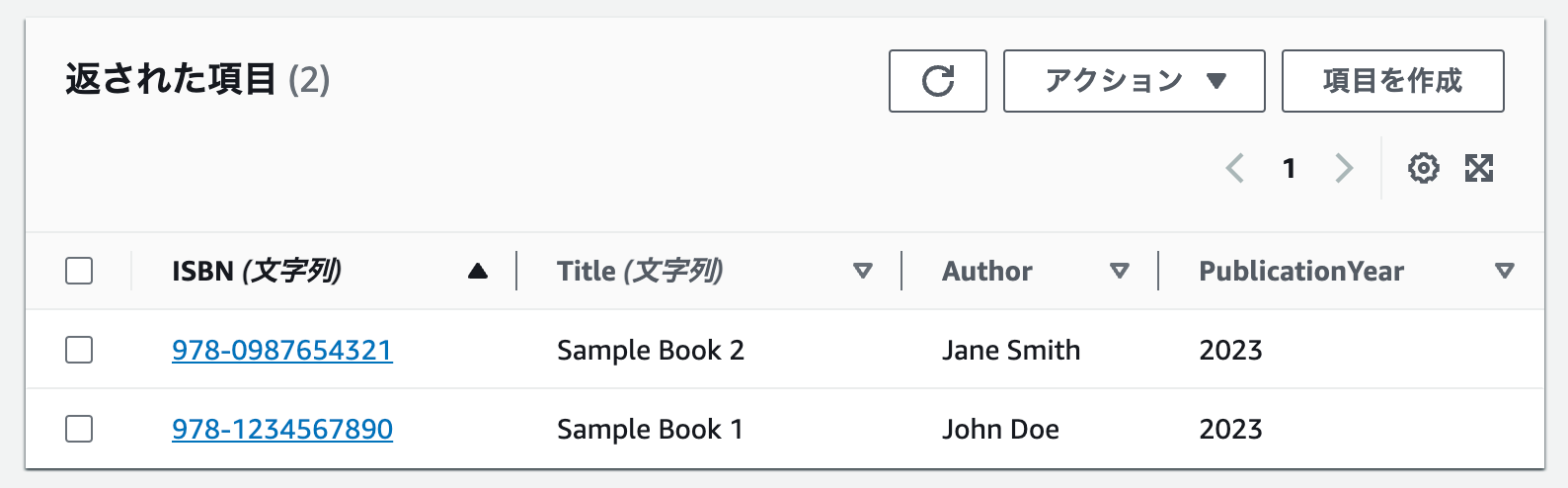
CSVダウンロード
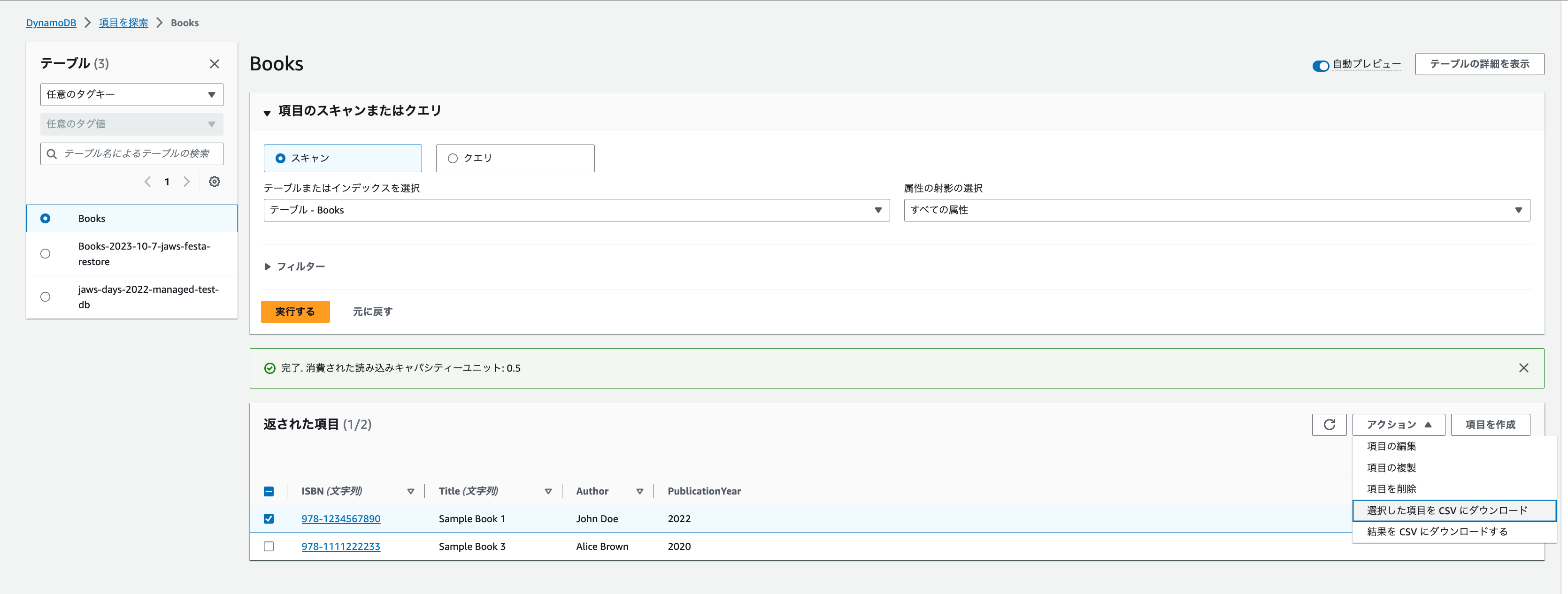
テーブルアイテムをCSVダウンロードしてみましょう。
- 選択した項目をダウンロード
- ダウンロードしたい項目にチェックボックスをつけます
- 「アクション」を押下して「選択した項目をCSVにダウンロード」を押します。
- 選択した項目のみダウンロードされます。
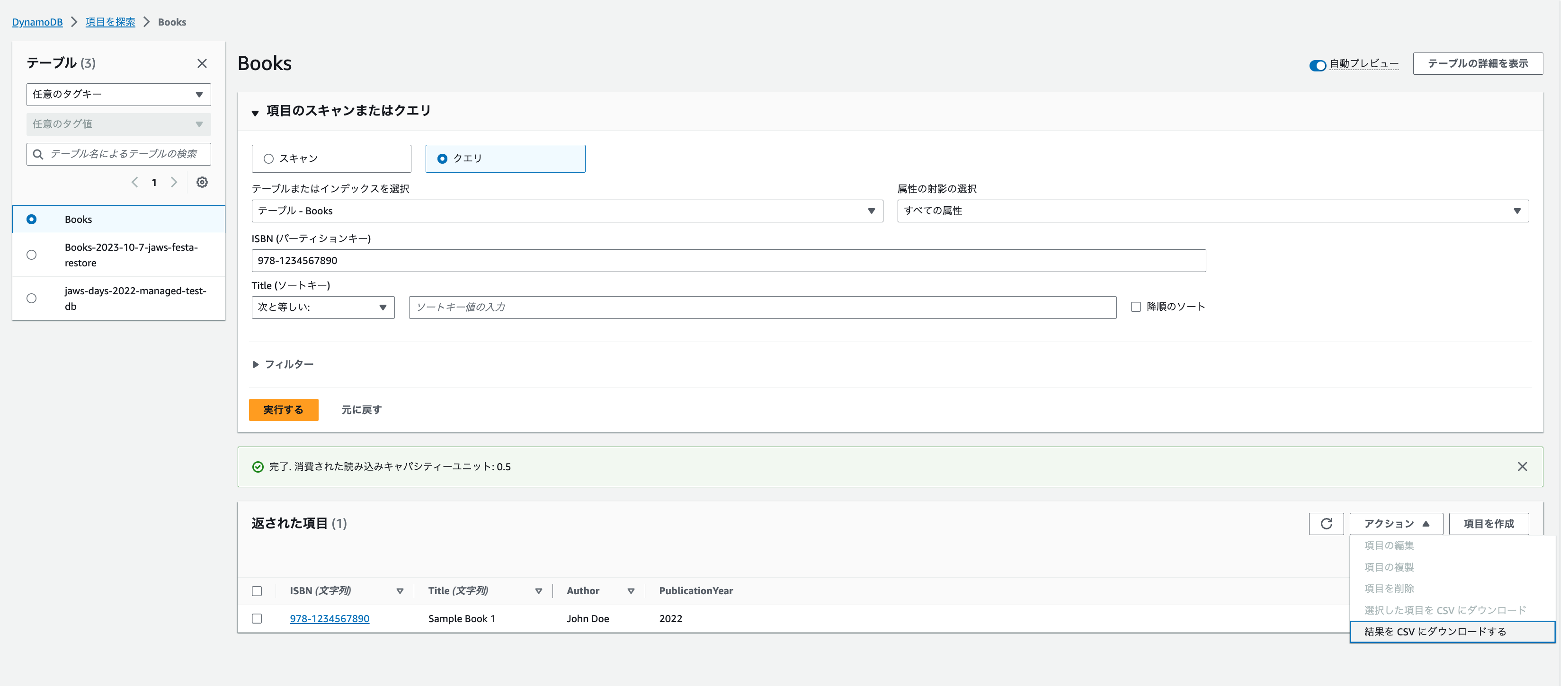
- 検索した結果をダウンロード
- 「項目のスキャンまたはクエリ」にて次のように設定して「実行」を押して検索します。
- 「クエリ」
- パーティションキー「978-1234567890」
- 返された項目にてチェックボックスをつけずに
「アクション」を押下して「結果をCSVダウンロードする」 - 検索された結果がダウンロードされます。
- 「項目のスキャンまたはクエリ」にて次のように設定して「実行」を押して検索します。
インデックスの追加
ここではグローバルセカンダリインデックスの追加とその動きを見ていきましょう。
インデックスタブを開く
![[9005502645341738] スクリーンショット 2023-10-07 1.23.07](https://mimemo.s3-ap-northeast-1.amazonaws.com/attachment/1fa98e49-fcdf-48e7-8bec-4e7946f4bbdb.png)
インデックスの作成をクリックする
![[9005502645148844] スクリーンショット 2023-10-07 1.26.17](https://mimemo.s3-ap-northeast-1.amazonaws.com/attachment/484e9933-30c9-445f-afbf-0e5201e20bda.png)
- インデックスの詳細に必要な値を入力する
- パーティションキー:
Title - インデックス名:
Title-All-Index ![[9005502642510468] スクリーンショット 2023-10-07 2.10.16](https://mimemo.s3-ap-northeast-1.amazonaws.com/attachment/1f8024a2-d8b7-4325-972f-a12292438888.png)
- パーティションキー:
- インデックスキャパシティーはデフォルト値のまま
![[9005502644969926] スクリーンショット 2023-10-07 1.29.16](https://mimemo.s3-ap-northeast-1.amazonaws.com/attachment/1e0f1e54-52a1-42d7-a736-96cca1f33a30.png)
- 属性の射影もデフォルト値のまま
![[9005502644904375] スクリーンショット 2023-10-07 1.30.02](https://mimemo.s3-ap-northeast-1.amazonaws.com/attachment/492b3248-a112-4268-af42-c5aa543f07c1.png)
インデックスの作成をクリックする
![[9005502644562107] スクリーンショット 2023-10-07 1.36.06](https://mimemo.s3-ap-northeast-1.amazonaws.com/attachment/7c050d20-1562-4b85-8c13-8146959e3641.png)
- 状態が
アクティブになるまで待つ
![[9005502644391946] スクリーンショット 2023-10-07 1.38.54](https://mimemo.s3-ap-northeast-1.amazonaws.com/attachment/21f13b53-6cc8-4110-aa9d-ed90bc558444.png)
![[9005502643873292] スクリーンショット 2023-10-07 1.47.40](https://mimemo.s3-ap-northeast-1.amazonaws.com/attachment/2f78d726-a1bc-45b9-96c9-2cf73324c001.png)
- Itemを追加する
- ISBN:
97848840230926 - Title:
海の底 - Author:
有川浩
- ISBN:
- Itemを追加する
- ISBN:
9784043898022 - Title:
海の底 - Author:
有川浩
- ISBN:
- クエリでインデックスを指定して検索する
- クエリ
- テーブルまたはインデックスを選択:
インデックス - Title-All-Index - Title (パーティションキー):
海の底 ![[9005502642996970] スクリーンショット 2023-10-07 2.02.07](https://mimemo.s3-ap-northeast-1.amazonaws.com/attachment/1822a73f-df6f-489d-a751-93cfe40d4fbd.png)
2件、タイトルで検索ができました。
グローバルセカンダリインデックスは、パーティションキーを指定して一意に決まらない唯一のインデックスなのです。
バックアップ
テーブルのバックアップ操作をやってみましょう。
バックアップの作成
バックアップのタブを選択します。
- バックアップの作成を選択します。
- オンデマンドバックアップを作成を選択します。
- ソーステーブルに「Books」
- バックアップ名に「Books-2023-10-7-jaws-festa」
- 「バックアップの作成」をクリックします。
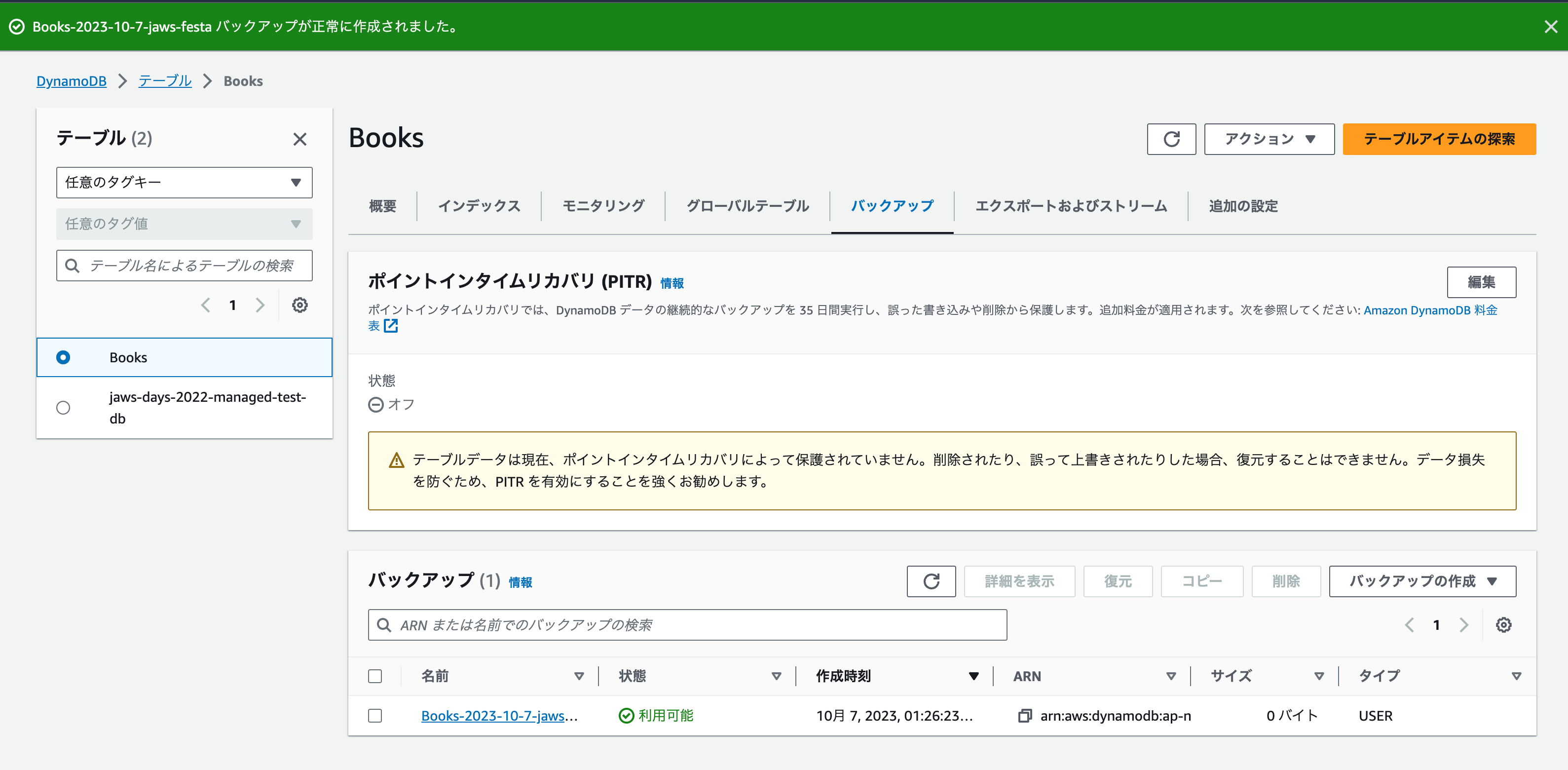
バックアップできました!🎉
バックアップの復元
- 「Books-2023-10-7-jaws-festa」のチェックボックスを選択します。
- 「復元」をクリックします。
- 「セカンダリインデックス」は「テーブル全体の復元」を選択します。
- 「復元先 AWS リージョン」は「同じリージョン (東京)」を選択します。
- 「保管中の暗号化の設定」は「Amazon DynamoDB が所有」を選択します。
- 「復元」をクリックします。
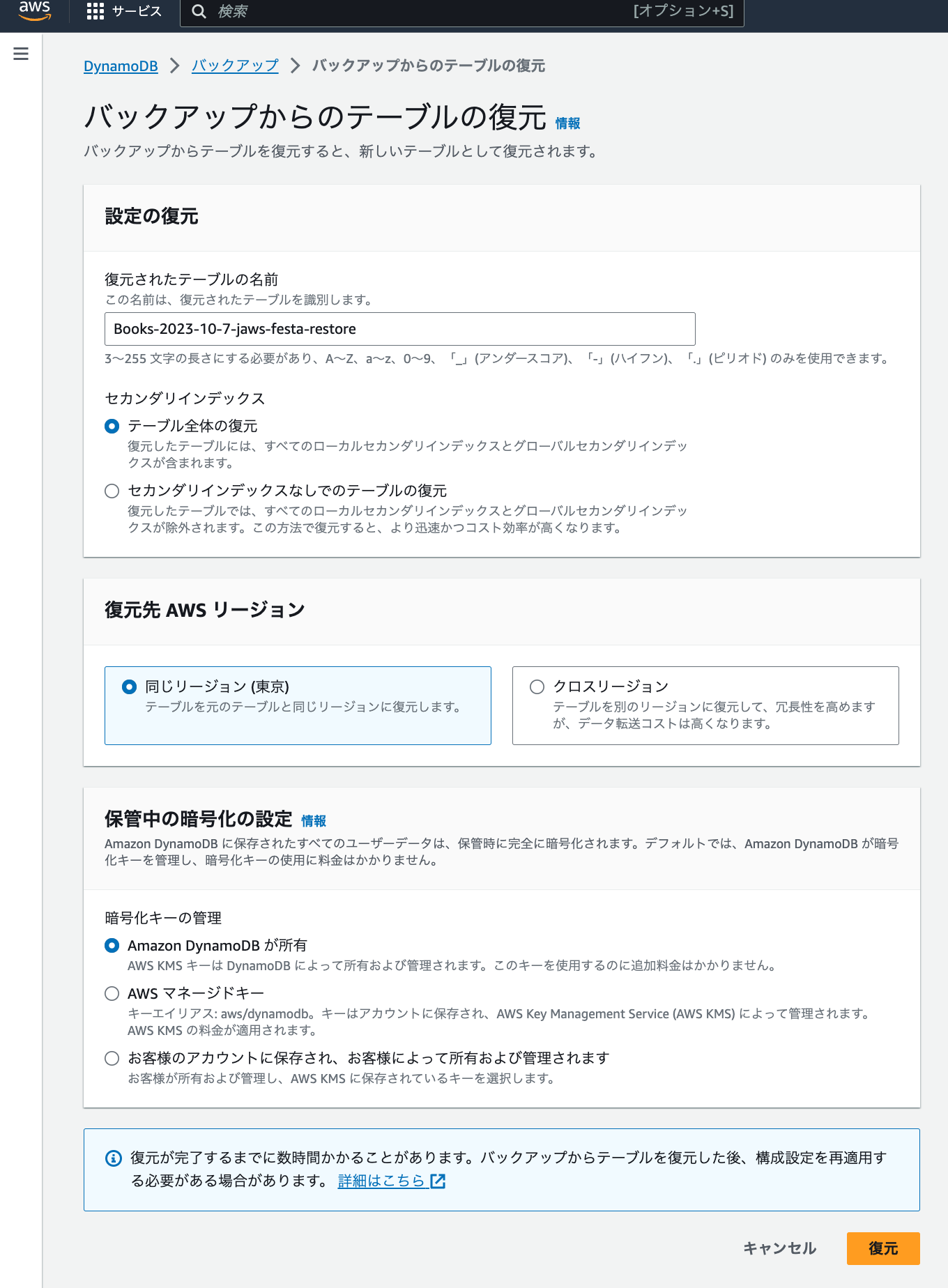
テーブルの復元にはしばらく時間がかかりますが、テーブルが復元中かどうかの状態などを一覧から確認できます。今回のデータ量だと、5~10分程度で完了します。
復元出来ました!🎉
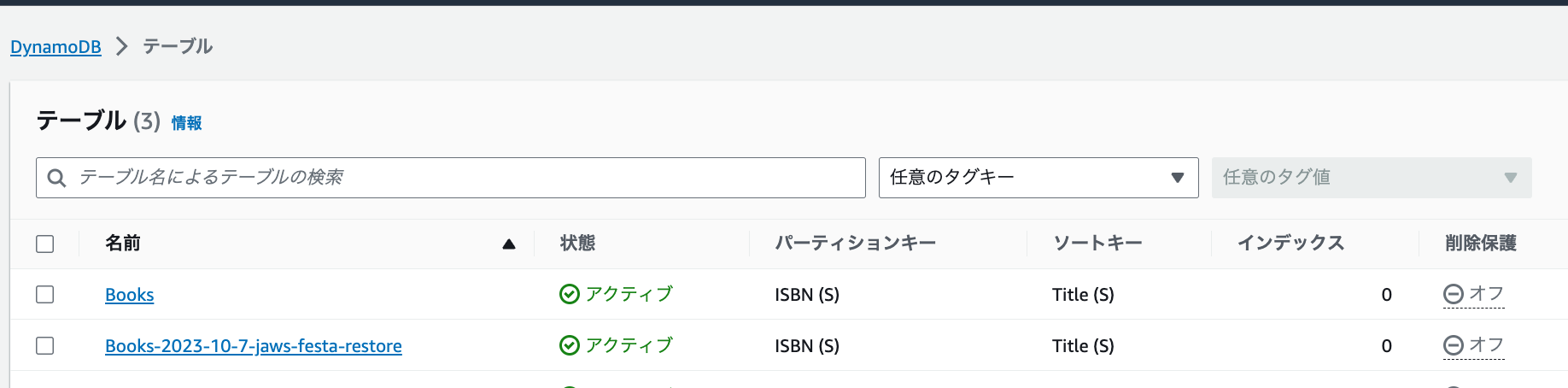
2-6. お片付け
テーブルを削除
- 削除するテーブルを選択します
- 「削除」をクリックします

- 確認を入力します
- 「削除」をクリックします

END
Close